
Paper: Volley: Accelerating Write-Read Orders in Disaggregated Storage
Motivation
为了减少访问远程存储带来的 I/O 开销,计算服务器通常会使用一部分 DRAM 作为写回缓存,来存储应用数据和缓冲频繁访问的数据。当缓存满时,如果需要读取新的数据,就必须腾出空间。这就需要进行缓存驱逐操作,将缓存中的脏页写回到远程存储设备,然后再从远程存储设备读取所需的数据。由于读取操作必须等待写入操作完成,这种顺序执行导致了 I/O 操作的停滞:
- 写入操作完成后,读取操作才能开始(否则导致脏页被读取页覆盖,从而造成数据不一致性)
- 这种等待时间在高并发的环境中尤为明显,因为现代高性能网络和存储设备(如支持 200Gbps 带宽的 RDMA NIC 和每秒处理百万次 I/O 请求的 NVMe SSD)可以同时处理多个 I/O 请求。
- 当系统不能并行执行写入和读取操作时,这些高性能设备的潜力无法得到充分利用,从而导致整体性能下降。
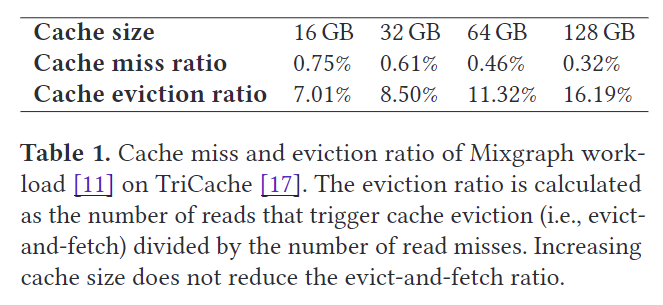
当增加 Cache 大小,evict 比例会增大(违反直觉 —— Even counter-intuitively),这会进一步扩大有序读写的性能开销。
目前有两种直接的方法来缓解这种读写有序性带来性能开销:
- 利用多个后台清理线程:但是随着缓存的频繁访问,脏块还是会聚集因为处理写命令操作需要很长时间
- 利用 NIC target offload 模式,它提供了更短的 I/O 路径,但是实验表明它仍然无法有效解决 NVMe-oF 中有序读写导致的 I/O 停顿
读写顺序在回写缓存中很常见,一旦需要保证读写顺序,性能就会被严重影响。
NVMe-over-Fabrics 协议(NVMe-oF)
NVMe-over-Fabrics(NVMe-oF)是一种流行的远程存储访问协议,它扩展自 NVMe 协议,以其低延迟(微秒级)和高并行性而闻名 。
NVMe-oF 协议有两个主要组件:
- 发起端(initiator)
- 目标端(target)
发起端首先连接到目标端暴露的存储设备,创建提交队列和完成队列,然后通过提交队列发送 I/O 命令,并通过完成队列接收执行结果。NVMe-oF 支持多种网络传输方式,包括 RDMA 和 TCP 。
在 NVMe-oF 协议中,写操作和读操作的流程如下:
- Write I/O Operation:
- 发起方将 64B NVMe 命令写入预注册的内存缓冲区并发出
RDMA_SEND命令。发送数据有两种选择:push&pull。pull:目标端通过 RDMA_READ 从发起端拉取数据,这要求 NVMe 命令包含发起端虚拟内存地址所呈现的数据源地址。push:发起者将封装内的数据块与 I/O 命令一起搭载,并使用 RDMA_SEND 将它们一起发送。这样,RDMA 使用scatter-gather列表来排列 NVMe 命令和数据块。
- Target 组装新的 NVMe 写命令,源地址为自己的数据块虚拟内存地址,并将该命令下发到本地 SSD。
- Target 从本地 SSD 获取完成响应,并通过 RDMA_SEND 组装一个完成条目来通知initiator完成。
- 发起方将 64B NVMe 命令写入预注册的内存缓冲区并发出
- Read I/O Operation:
- Read I/O 操作的工作流程与 Write I/O 操作类似。发起方使用 RDMA_SEND 向目标方发送读取命令。然后,目标从其本地 SSD 读取数据块。最后,它使用 RDMA_WRITE 向发起者发送数据块,并使用 RDMA_SEND 发送完成响应。
⭐RDMD_WRITE 与 RDMA_SEND 的区别:
- RDMA_WRITE 操作是将数据从本地内存直接写入到远程节点的内存。此操作由本地节点(发起端)发起,并且直接在远程节点的内存中指定位置写入数据,无需目标端的 CPU 参与。
- RDMA_SEND 操作是将数据从本地内存发送到远程节点,并由远程节点的应用程序处理。接收到的数据会放入目标端的接收缓冲区,由目标端的 CPU 进行处理。
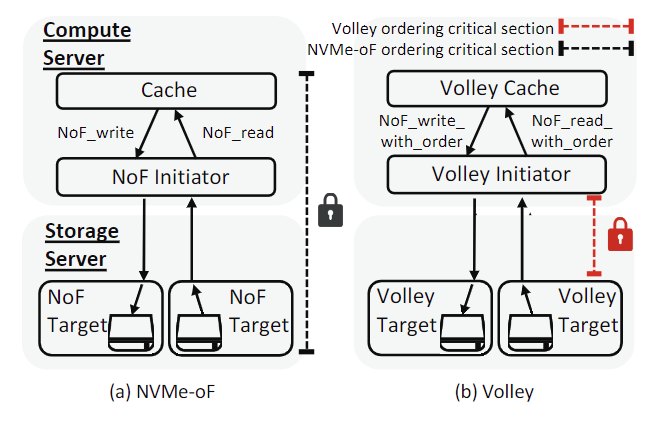
🌀NVMe-oF 支持两种模式,具体取决于 CPU 的参与情况(图 2)。
- CPU 模式:所有命令和数据块首先传输到 CPU 内存,然后发送到 SSD
- NIC target offload 模式:I/O 命令和数据块直接从 NIC 发送到 SSD,绕过 CPU。还可以启用推送,通过一起发送 I/O 命令和数据块来传输小尺寸的封装内数据块。
与 CPU 模式相比,卸载模式提供了更短的 I/O 路径。首先,对于非持久写请求,当数据块到达 NIC 而不是 SSD 时,卸载模式向发起者返回完成响应。其次,绕过 CPU 减少了每个 I/O 操作的 PCIe 往返次数。
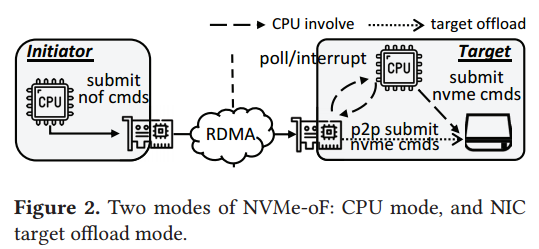
Volley Design
Volley 协议通过允许写入和读取操作同时进行,解决了上述问题。具体来说:
- Volley 将写读顺序的关键部分最小化到驱动程序级别,这意味着只在写操作的数据块即将被覆盖时,才会严格遵守顺序。
- 这样,其他组件可以并行处理写入和读取操作,充分利用现代网络和存储硬件的高性能。
在 Volley 协议中,一个 Storage Server 包含多个 Target,每个 Target 配备了多个 NVMe SSDs 。
- 每个 Storage Server 包含多个 Target:这些 Target 处理从 Initiator 接收到的 I/O 命令。
- 每个 Target 配备多个 NVMe SSDs:这些 SSD 用于存储数据块,执行读写操作。
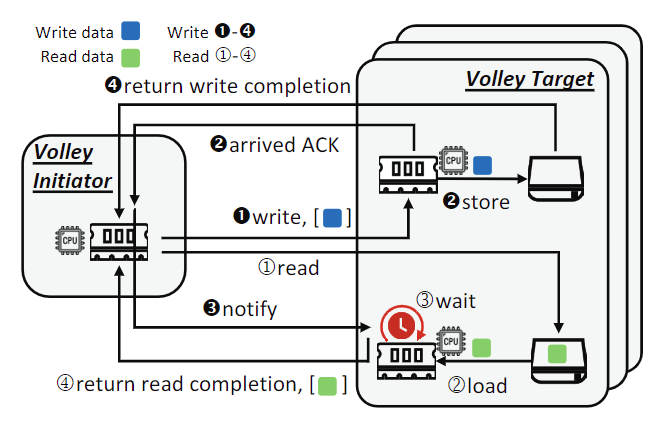
主要工作流程如下图,主要凭借多个 Target 之间的协作完成,一个 Target 用于写入,一个 Target 用于读取,二者同时进行,当写入完的 Target 就通知读取的 Target 可以返回给 Initiator。注意,尽管 Read④ 可能比 Write④ 先返回给 Initiator,但这不影响 Initiator 按顺序完成 Write 和 Read。
感觉整体设计做了一个不错的 Trick,但是行之有效。
Evaluation
- V-TriCache 是专为计算场景(如超大规模数据处理、数据分析等)设计的缓存系统。它的主要目的是优化内存管理,尤其是在物理内存不足以容纳所有工作负载时。
- V-Cache 是为虚拟机存储设计的用户态写回缓存系统,旨在优化虚拟机的存储性能,特别是当虚拟机需要频繁进行读写操作时。
使用 V-TriCache 和 V-Cache 的主要原因在于它们能够有效利用 Volley 协议带来的并行处理优势,减少传统逐出-获取顺序带来的性能瓶颈,从而在计算和存储场景中显著提升系统性能和效率。
SOTA (state-of-the-art)
本文由 Yikun Wu 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。




