
Paper: An Empirical Guide to the Behavior and Use of Scalable Persistent Memory
Slide: View the slides
0. 持久化内存调研
企业级 SSD 可以提供 10 微秒级别的响应时间,DRAM 的响应时间大约是 100 纳秒这个级别。SSD 的响应时间和 DRAM 有着差不多 100 倍的差距。而 DRAM 和最后一级 CPU Cache 的响应时间只有 8~10 倍的差距。很明显,DRAM 和 SSD 之间存在比较巨大的性能鸿沟。所以在设计应用程序的时候,需要特别注意 I/O 相关的操作,避免 I/O 成为系统的性能瓶颈。
PMEM 提供亚微秒级别的延迟时间。从成本、性能、容量上看,PMEM 是位于 DRAM 和 SSD 之间的一层存储。PMEM 的出现,填补了 DRAM 和 SSD 之间的性能鸿沟,同时也将影响存储软件的架构设计。
「学术界」在很早以前就开始了对持久化内存的研究,比如:
- NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories
- Bztree: A High-performance Latchfree Range Index for Non-volatile Memory
- Let’s talk about storage: Recovery methods for nonvolatile memory database systems
- ……
但以前没有真实的持久化内存硬件,只能基于软件模拟器进行仿真测试。直到 2019 年 4 月,Intel 发布了第一款企业级的持久化内存 —— Intel Optane DC Persistent Memory(下面简称 Optane DIMMs)。
由于模拟器没法百分之百模拟硬件,之前通过模拟器仿真出来的研究结果和真实硬件下的测试结果还是有一些差别的。在 FAST’20 上,有人发表了一篇论文,介绍 Intel Optane DC Persistent Memory 的使用特点 —— An Empirical Guide to the Behavior and Use of Scalable Persistent Memory。
Intel Optane DC Persistent Memory 是目前唯一一款量产的持久化内存,同时目前也只有 Intel 的 Cascade Lake 处理器支持这款持久化内存。
Intel Optane DC Persistent Memory

如上图所示,Optane DIMMs 采用和 DRAM 一样的 DIMM 接口。这意味着,Optane DIMMs 可以直接插在内存插槽上,通过内存总线和 CPU 通信,而 CPU 也可以通过指令直接操作 Optane DIMMs。
Optane DIMMs 的持久化
Optane DIMM 有两种工作模式:Memory Mode 和 App Direct Mode。
- Memory Mode 简单说就是把 Optane DIMMs 当成易失性内存使用,把 DRAM 当作 CPU 和 Optane DIMMs 之间的 cache,并且 DRAM 对外不可见(就像 CPU 的多级 cache 对外也不可见)。基于 Memory Mode 的工作模式,可以通过应用无感知的方式,解决一些内存数据库(比如 Redis、Memcached)单机 DRAM 容量不足或成本过高的问题。
- App Direct Mode 将 Optane DIMMs 当成一个持久化设备来使用,直接通过 CPU 指令读写 Optane DIMMs,不需要经过 DRAM。应用可以使用能够感知持久化内存的文件系统(比如 EXT4-DAX、XFS-DAX、NOVA)或其他组件(比如 PMDK)来管理、操作持久化内存设备。
Memory Mode 由于不考虑持久化问题,一般情况下将其当做一块更大的 DRAM 使用即可。
在 App Direct Mode 工作模式下,尽管 Optane DIMMs 设备本身是非易失的,但是由于有 CPU Cache 的存在,当设备掉电时,“还没写入” Optane DIMMs 的数据还是会丢失。
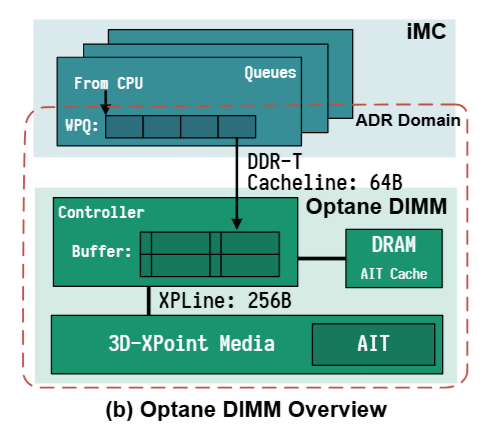
为了数据的持久化,Intel 提出了 Asynchronous DRAM Refresh(ADR)机制。ADR 机制保证,一旦写请求达到 ADR 中的 WPQ(Write Pending Queue),就能保证数据的持久性。除了 WPQ,Optane DIMMs 上也有缓存数据,ADR 机制同样会保证这部分数据的持久化。
但是,ADR 机制无法保证 CPU Cache 中的数据的持久化。为了保证 CPU Cache 上的数据持久化,可以调用 CLFLUSHOPT 或 CLWB 指令,将 CPU Cache Line Flush 到 Optane DIMMs 中:
CLFLUSHOPT指令执行完成后,CPU Cache 中的相关数据被逐出。CLWB指令执行完成后,CPU Cache 中的相关数据依然有效。
由于,CLFLUSHOPT 和 CLWB 指令都是异步执行的,所以一般需要跟随一个 SFENCE 指令,以保证 Flush 执行完成。
CPU 还提供了 NTSTORE(Non-temporal stores)指令可以做到数据写入的时候 bypass CPU Cache,这样就不需要额外的 Flush 操作了。
Optane DIMMs 的读写延迟
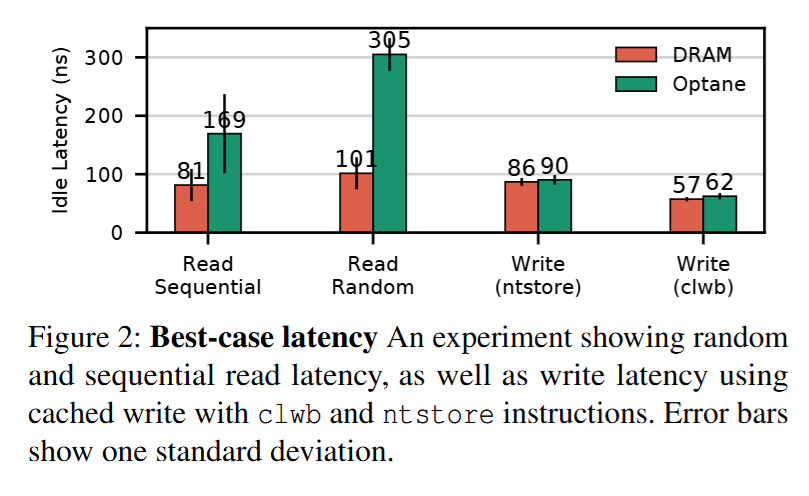
从论文中的测试数据看,Optane DIMMs 的读延迟是 DRAM 的 2~3 倍。另外,Optane DIMMs 顺序读的速度是随机读的 1.8 倍,相比之下,DRAM 顺序读的速度只有随机读的 1.2 倍。
由于写入 Optane DIMMs 的数据只需要到达 ADR 的 WPQ 即可,DRAM 和 Optane DIMMs 的写入延迟接近。
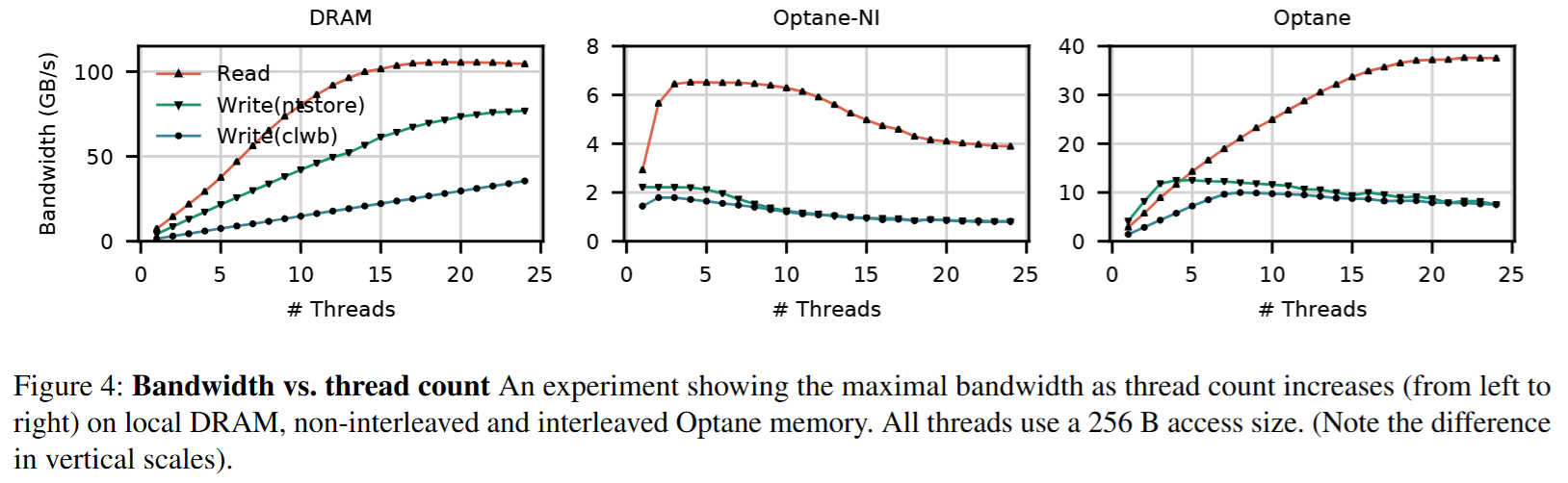
图正上方的三个数字的含义是:load 线程数 / ntstore 线程数 / store + clwb 线程数
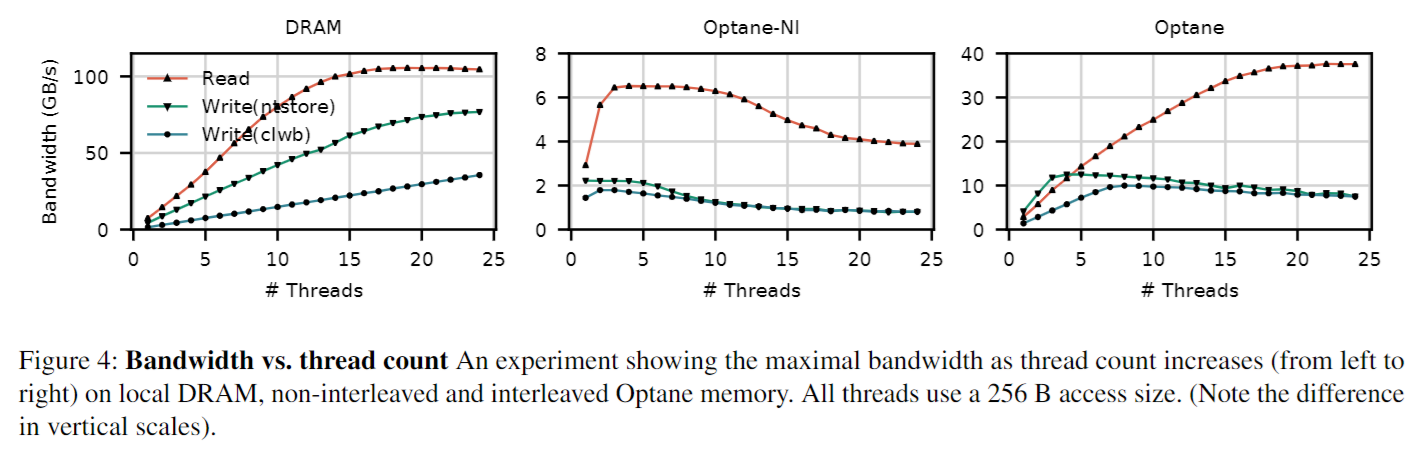
DRAM 的读写带宽几乎不受数据大小和并发线程数的影响,速度很快并且非常稳定。对 DRAM 来说,读带宽大约是写带宽的 1.3 倍,但是 Optane DIMMs 读带宽是写带宽的 2.9 倍。
Optane DIMMs 的读写带宽在读写数据大小为 256B 时达到最大值。这是因为 Optane DIMMs 虽然支持字节寻址,但是每次读写的最小粒度是 256B。当一次读操作小于 256B 时,会浪费一些带宽。当一次写操作小于 256B 时,就会被转换成一次 read-modify-write,造成写放大(这点和 SSD 很像,只不过粒度更小,SSD 一般是大于等于 4KB)。
最后,根据上图的最右所示,Optane DIMMs 在并发线程数较多且访问数据为 4KB 时,带宽掉了个大坑 —— 这和 Optane DIMMs 内部结构有关。主要原因有两个:
- 对内部 buffer/cache 和内存控制器(iMC) 的争用。
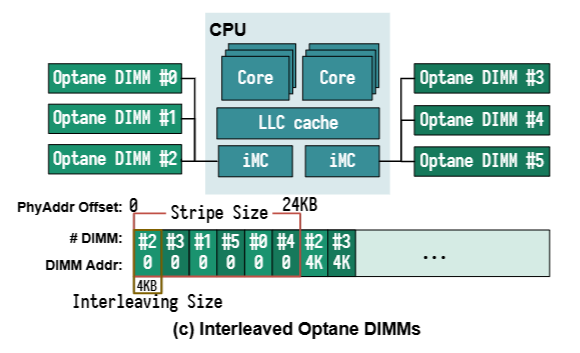
- 由于多条 Optane DIMMs 采用 4KB 交叉的方式组织成一个完整的持久化内存地址空间。每次访问对齐的 4 KB,请求都只能落在一条 Optane DIMMs 上,无法发挥多条 Optane DIMMs 通道并行执行的能力。
论文的最后总结了 4 条 Optane DIMMs 的最佳实践:
- Avoid random accesses smaller than < 256 B. 避免小于 256 字节的随机读写。
- Use non-temporal stores when possible for large transfers, and control of cache evictions. 大内存操作时,使用 ntstore 指令绕过 CPU Cache。
- Limit the number of concurrent threads accessing a 3D XPoint DIMM. 限制一个 Optane DIMMs 通道的并发数。
- Avoid NUMA accesses (especially read-modify-write sequences). 避免 NUMA 访问。其实内存也一样,远端内存比本地内存要慢不少,这个问题在 Optane DIMMs 表现更突出,需要特别注意。
更具体的内容,建议大家去看论文。
Basic Performance Measurements of the Intel Optane DC Persistent Memory Module 这一篇也比较有代表性,数据更详细。
PMDK 简介
前面说了,为了保证数据的持久化,需要在合适的地方用一些底层的 CPU 指令来保证。这样做有两个明显的缺点:
- 太过于底层,代码写起来麻烦。
- 可移植性差,不同 CPU 的指令是不一样的。
为了简化基于持久化内存的应用开发,Intel 开发和维护了 Persistent Memory Development Kit 这个开源组件。虽然这个组件目前由 Intel 开发和维护,但是理论上 PMDK 是与具体的硬件平台无关的——虽然现在依然只有 Intel 的一款持久化内存量产了。
PMDK 中的库可以分成两大类:
- Volatile libraries。如果不关心数据的持久化,只想通过 persistent memory 扩展内存,可以使用这一类库。
- Persistent libraries。如果想要保证数据的 fail-safe,需要使用这一类库。
Volatile libraries
- libmemkind 提供 malloc 风格的接口,可以将持久化内存当成 DRAM 使用。
- libvmemcache 是一个针对持久化内存的特点优化的易失性 LRU 缓存。
Persistent libraries
- libpmem 提供比较底层的操作持久化内存的接口,比如 pmem_map 类似 mmap、pmem_memcpy 类似 memcpy,具体可以参考官方文档。
- libpmemobj 提供基于持久化内存的对象存储能力。
- libpmemkv 是一个基于持久化内存的嵌入式 Key-Value 引擎,基于 B+ 树实现,针对读优化(libpmemkv 的内部实现)。
- libpmemlog 提供 append-only 的日志文件接口。
- libpmemblk 提供块存储接口,简单说就是将持久化内存抽象成一个数组。
除此之外,PMDK 还提供了一些工具和命令用于辅助开发和部署基于持久化内存的应用,具体参考 PMDK 官方文档吧。
1. Optane Memory
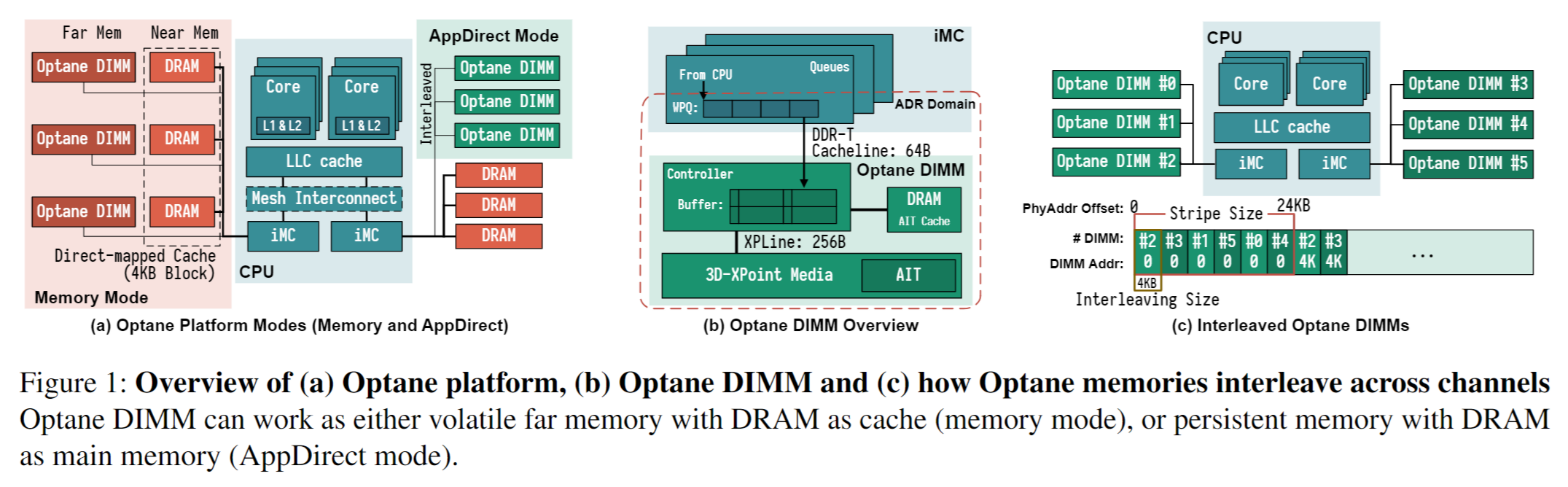
Figure 1
Optane DIMM 位于内存总线上,并连接着处理器的 iMC (integrated memory controller)。每个 CPU 包含 1 或 2 个处理器芯片,其中包含单独的 NUMA 节点。每个 CPU 芯片都有 2 个 iMCs,每个 iMC 都支持 3 个通道。因此一个 CPU 芯片可在其 2 个 iMCs 上支持 6 个 Optane DIMMs。
为了保证持久化,iMC 位于 ADR (asynchronous DRAM refresh) 区域,确保能在电源故障时 (<100us) 刷新到 ADR domain。
Optane DIMM 支持两种模式:
- Memory:相当于直接作为非易失性内存使用
- APP Direct:提供持久性但不使用 DRAM cache
因为 Optane DIMM 既是【字节寻址】又提供【持久化】,所以可以作为主存设备,也可以作为持久化设备。本文聚焦于持久化使用,在 Section 6 会讨论如何将 Optane DIMM 作为易失性内存使用。
Figure 2
iMC 使用 DDR-T 接口以 Cacheline(64 bytes)粒度与 Optane DIMM 进行通信,该接口与 DDR4 共享机械和电气接口,但使用允许异步命令和数据时序的不同协议。
对 NVDIMM 的内存访问首先到达 on-DIMM controller(称为 XPController),用来协调对 Optane 介质的访问。
与 SSD 相同,Optane DIMM 也会执行内部地址转换以实现磨损均衡和坏块管理,并且维护了 AIT (address indirection table) 用于转换。
因为 3D-XPoint 物理介质的访问粒度为 256 bytes(称为 XPLine),XPController 将较小的请求转为较大的 256-bytes 访问,read-modify-write 操作会导致写放大问题。
XPController 有一个小 write-combining buffer(称为 XPBuffer)用于合并相邻写入。
2. LATTester | Performance Characterization
The program and dataset are available at https://github.com/NVSL/OptaneStudy.
描述 Optane 内存具有挑战性,原因有二。
- 首先,底层技术与 DRAM 有很大不同,但公开的文档很少。
- 其次,现有工具主要根据局部性和访问大小来衡量内存性能,但我们发现 Optane 性能也在很大程度上取决于内存交错和并发性。持久性为性能测量增加了额外的复杂性。
为了充分了解 Optane 内存的行为,我们构建了一个名为 LATTester 的微基准测试工具包。为了准确测量 CPU 周期数并最大限度地减少虚拟内存系统的影响,LATTester 在内核中作为虚拟文件系统运行,并访问 Optane DIMM 的预填充(即无页面错误)内核虚拟地址。LATTester 还将内核线程固定到固定的 CPU 内核并禁用 IRQ 和缓存预取器。除了简单的延迟和带宽测量外,LATTester 还在 CPU 和 NVDIMM 上收集大量硬件计数器。
2.1 Typical Latency
对于 DRAM 来说,随机与顺序的差距为 20%,但对于 Optane 内存来说,这一差距为 80%,而这一差距是 XPBuffer 造成的。
总体而言,Optane 的延迟差异非常小,除了极少数“异常值”,我们将在下一节中进行研究。Optane DIMM 的顺序读取延迟差异较大,因为第一个缓存行访问将整个 XPLine 加载到 XPBuffer 中,而接下来的三个访问读取缓冲区中的数据。
Cacheline: 64 bytes
XPLine: 256 bytes

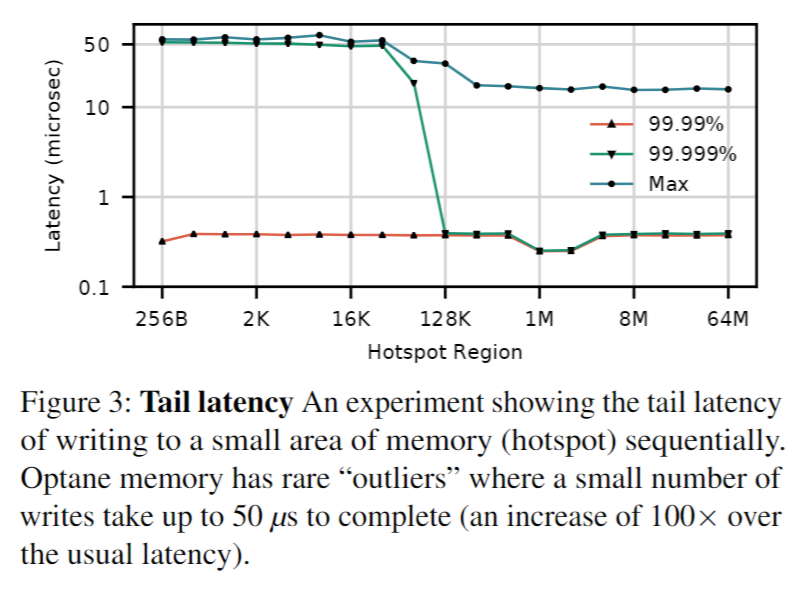
2.2 Tail Latency
这些峰值很少见(占访问的 0.006%),但它们的延迟比常见的 Optane 访问高出 2 个数量级。我们怀疑这种影响是由于出于磨损均衡或热问题而进行的重新映射,但我们不能确定。
2.3 Bandwidth
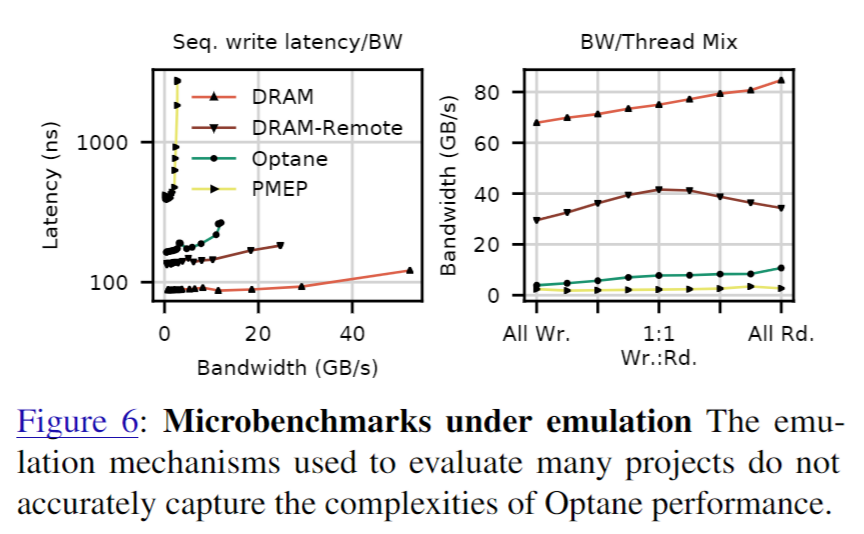
3. Comparison to Emulation
下面,我们使用微基准测试将这些 NVM 模拟技术与真实的 Optane 进行比较,然后提供一个案例研究,说明这些差异如何影响研究结果。
图 6(左)显示了 NVM 仿真机制(例如 PMEP、DRAM-Remote、DRAM)与真实 Optane 内存的写入延迟/带宽曲线。图 6(右)显示了与读取器/写入器线程数相关的带宽(所有实验都使用固定数量的线程来提供最大带宽)。
请注意,PMEP 是一个专用的硬件平台,因此其性能数字不能直接与我们在其他实验中使用的系统进行比较。这些图中的数据表明,没有任何一种仿真机制能够捕捉 Optane 行为的细节——所有方法都与真实的 Optane 内存大相径庭。他们未能捕捉 Optane 内存对顺序访问和读/写不对称的偏好,并对设备延迟和带宽给出了非常不准确的猜测。
4. Best Practices for Optane DIMMs (Guidelines)
提炼出四个指导基于 Optane 系统的原则:
(1)避免小于 256 B 的随机访问
(2)对于大容量传输,尽可能使用非临时存储,并控制缓存驱逐
(3)限制同时访问Optane DIMM的线程数量
(4)避免跨NUMA节点的混合或多线程访问(尤其是读取-修改-写入序列)
4.1 Avoid small random accesses
在内部,Optane DIMM 以 256 B 的粒度更新 Optane 内容。这种粒度加上较大的内部存储延迟意味着较小的更新效率低下,因为它们需要 DIMM 执行内部读取-修改-写入操作,从而导致写入放大。访问表现出的局部性越少,对性能的影响就越严重。
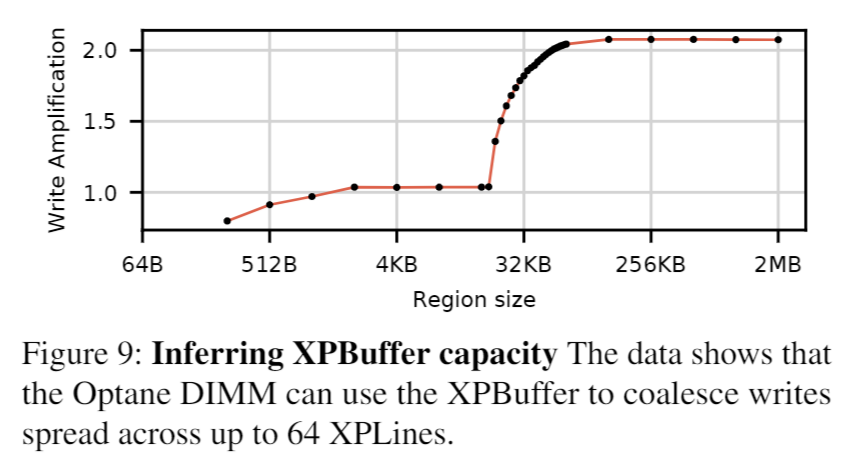
通过实验发现,XPBuffer 大小为 16KB(64 个 XPLines)
案例研究:
- RocksDB: 在RocksDB中,使用持久性内存表导致了许多小存储操作,这些操作的局部性较差,导致有效写入率(EWR)较低。而基于FLEX的WAL优化使用顺序(且更大的)存储操作,得到了更高的EWR。
- NOVA文件系统: NOVA通过增加日志条目的大小和避免一些写时复制操作来提高性能。NOVA-datalog将数据嵌入到日志中,将随机写入转换为顺序写入。
实践建议:这些结果共同为最大化 Optane 存储效率提供了具体指导:避免使用小型存储,但如果不可能,则将每个 Optane DIMM 工作集限制为 16 kB。
4.2 Use non-temporal stores for large writes
写入持久内存时,程序员可以选择使用 clflush、clflushopt 或 clwb 指令来确保数据持久化。非临时存储(ntstore)指令可以直接写入持久内存,绕过缓存层次结构。
- Non-temporal store(非临时存储)是一种CPU指令,它允许数据直接写入内存,同时绕过CPU缓存(cache)层次结构。这种指令特别适用于优化内存密集型应用的性能,尤其是在处理大量数据传输时。

实践建议:
- 对于大于
64B的访问,使用clflush或clwb刷新缓存行,以提高带宽。 - 对于大于
512B的访问,使用非临时存储(ntstore)以降低延迟并提高带宽。
案例研究:
- PMDK 的微缓冲区技术:通过结合使用非临时存储和常规存储,可以根据对象大小优化性能。
4.3 Limit the number of concurrent threads accessing a Optane DIMM
Optane DIMM 的存储性能和 iMC 上的缓冲能力有限,难以同时处理多个线程的访问。
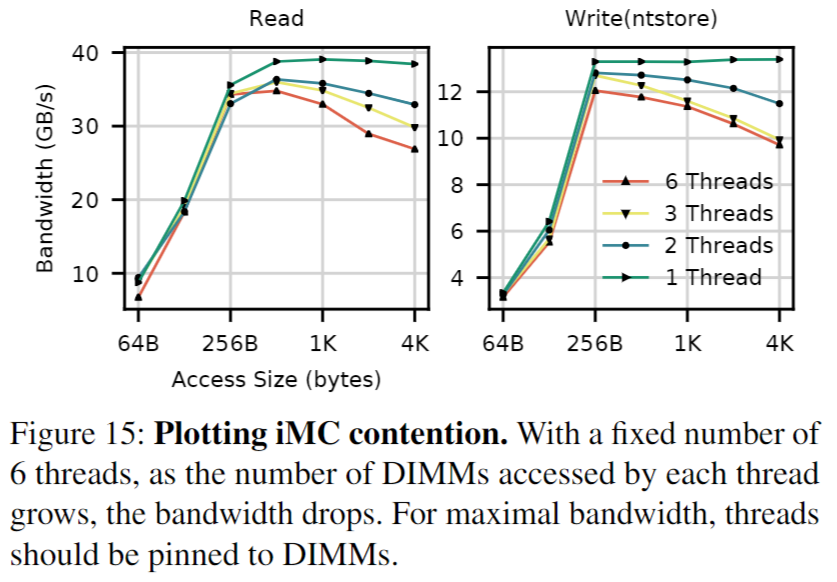
实践建议:
- 避免多个线程竞争同一 XPBuffer 空间,以减少驱逐和回写操作。
- 通过线程绑定到非交错的 Optane DIMMs,确保线程和 NVDIMMs 之间的均匀匹配,从而最大化每个 NVDIMM 的带宽。
案例研究:
- 多NVDIMM感知的NOVA:通过确保线程均匀地访问 DIMMs,优化后的NOVA在FIO基准测试中带宽提升了3%到34%。
4.4 Avoid mixed or multi-threaded accesses to remote NUMA nodes
Optane DIMM 的 NUMA 效应比 DRAM 更大,应尽量避免跨 socket 内存流量,特别是涉及多个线程的读写混合访问。
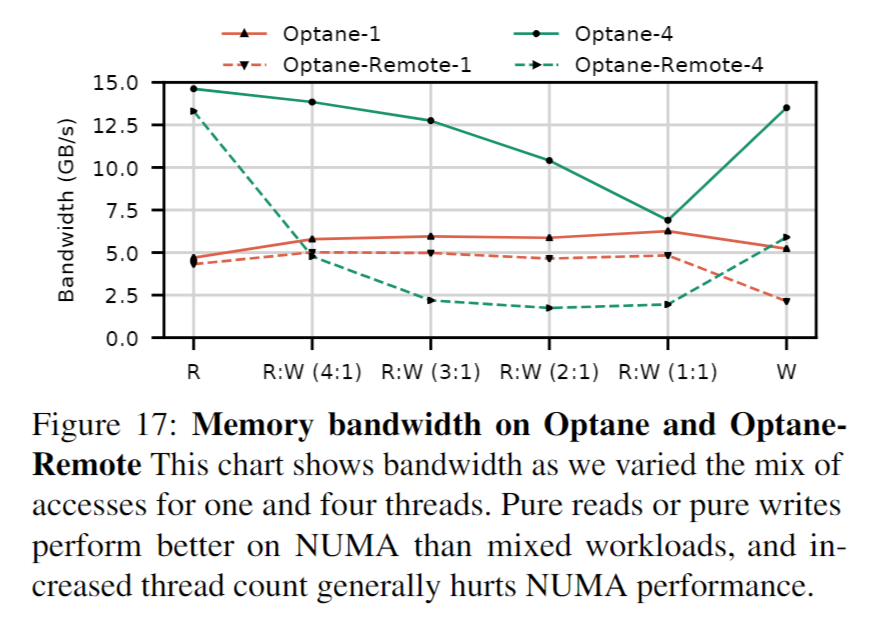
实践建议:
- 尽量在本地 Optane DIMM 上进行操作,以避免 NUMA 性能下降。
案例研究:
- PMemKV: 在PMemKV中,使用远程Optane DIMM会显著降低应用性能,尤其是在多线程环境下。
5. Related Work
关于 NVM 的数据一致性,可以参考:《面向非易失内存的数据一致性研究综述》
持久性内存编程的现有技术已经涵盖了系统堆栈,但直到最近,这些结果才在真正的 Optane 内存上进行了测试。大量的工作已经探索了事务内存类型抽象,以强制执行一致的持久状态 $[5,9,12,25,26,28,33,49]$。各种作者已经构建了复杂的 NVM 数据结构,用于日志记录、数据存储和事务处理 $[3,4,10,11,17,23,24, 27, 30, 35, 38, 39, 41, 45, 46, 50, 57]$。自定义 NVM 文件系统也已被探索 [13, 21, 34, 48, 52, 54–56, 62]
本文由 Yikun Wu 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。




