
Paper: TeRM: Extending RDMA-Attached Memory with SSD
Slide: View the slides
RDMA
远程直接内存访问(RDMA)作为一种高性能网络技术,在数据中心中应用广泛。RDMA 允许服务器将其内存区域暴露给客户端,客户端可以通过一边请求(one-sided requests)直接访问这些内存区域。RNIC(RDMA Network Interface Card)是处理请求的关键组件,RNIC 的主要功能是允许计算机在不需要 CPU 干预的情况下直接通过网络访问远程内存。以下是 RNIC 处理请求的一般流程:
RNIC 处理请求的流程
1. 初始化资源
在使用 RDMA 进行通信之前,需要初始化两个重要资源:队列对(Queue Pair, QP)和内存区域(Memory Region, MR)。
- 队列对(QP):QP 是与另一个节点通信的端点。QP 包含发送队列(Send Queue)和接收队列(Receive Queue),用于管理发送和接收操作。
- 内存区域(MR):MR 暴露应用程序虚拟内存中的一个区域,RNIC 可以访问这个区域。初始化 MR 时,驱动程序会将所有页面固定在物理内存中,并将虚拟地址到物理地址的映射存储在 RNIC 页表中。
2. RDMA 请求类型
RDMA 支持两种类型的请求:一边请求(One-sided Requests)和两边请求(Two-sided Requests)。
- one-sided request:包括 READ 和 WRITE 操作。这些请求不涉及远程 CPU,客户端可以直接访问远程 MR。
- two-sided request:包括 SEND 和 RECV(接收)操作。这些请求提供消息传递抽象,通常用于构建远程过程调用(RPC)。
3. RNIC 处理请求的流程
以下是 RNIC 处理一边 RDMA 请求(例如 READ 操作)的详细流程:
- 提交请求:
- 客户端通过 QP 提交 RDMA READ 请求,该请求包含源地址、目标地址和数据长度等信息。
- 请求传输:
- 客户端的 RNIC 将请求通过 RDMA 网络发送到服务器的 RNIC。
- 地址解析:
- 服务器的 RNIC 接收到请求后,从 RNIC 页表中查找目标虚拟地址对应的物理地址。
- 如果目标虚拟地址在 RNIC 页表中有效,RNIC 直接访问物理内存中的数据。
- 数据传输:
- RNIC 使用直接内存访问(DMA)引擎将数据从物理内存中传输到客户端指定的内存区域。
- 传输完成后,RNIC 发送完成通知(Completion Notification)给客户端,表示请求已完成。
4. RNIC 页错误处理
当 RDMA 请求访问的虚拟地址在 RNIC 页表中无效(例如数据在 SSD 上而不在物理内存中)时,会触发 RNIC 页错误。RNIC 页错误的处理流程如下:
- 触发页错误:
- RNIC 发现虚拟地址无效时,暂停 QP 并触发 RNIC 页错误中断。
- CPU 处理页错误:
- 驱动程序向操作系统内核请求虚拟到物理地址的映射。操作系统内核触发 CPU 页错误,将数据从 SSD 提升到物理内存,并更新 CPU 页表。
- 更新 RNIC 页表:
- 驱动程序更新 RNIC 页表中的映射,并恢复 QP,继续处理请求。
- 完成请求:
- 数据传输完成后,RNIC 发送完成通知给客户端。
RDMA READ/WRITE 与 RPC READ/WRITE 的区别
RDMA READ/WRITE 是 one-sided 操作,这意味着这些操作可以直接在远程内存区域上执行,而无需远程服务器的 CPU 参与。
RDMA READ
- 客户端通过QP(Queue Pair)提交READ请求,指定源地址、目标地址和读取长度。
- 客户端的RNIC(RDMA Network Interface Card)将请求发送到服务器的RNIC。
- 服务器的RNIC根据内部页表解析目标地址,从物理内存中读取数据并通过DMA传输回客户端。
- 请求完成后,客户端的RNIC通知客户端请求完成。
RDMA WRITE
- 客户端通过QP提交WRITE请求,指定源地址、目标地址和写入数据。
- 客户端的RNIC将数据通过DMA传输到服务器的RNIC。
- 服务器的RNIC根据内部页表解析目标地址,将数据写入服务器的物理内存。
- 请求完成后,客户端的RNIC通知客户端请求完成。
RPC (Remote Procedure Call) 是 two-sided 操作,需要客户端和服务端双方参与,RPC通常用于执行需要远程服务器逻辑处理的操作。
RPC READ
- 客户端发起一个RPC请求,包含要读取的数据地址和长度。
- 请求通过网络发送到服务器,服务器的CPU接收到请求并进行处理。
- 服务器的CPU根据请求读取内存数据,并将数据打包成响应消息。
- 服务器通过网络将响应消息发送回客户端。
- 客户端接收到响应消息,提取数据。
RPC WRITE:
- 客户端发起一个RPC请求,包含要写入的数据和目标地址。
- 请求通过网络发送到服务器,服务器的CPU接收到请求并进行处理。
- 服务器的CPU将数据写入指定的内存地址。
- 服务器通过网络发送确认消息回客户端。
- 客户端接收到确认消息,确认写入操作完成。
RDMA 实现较为复杂,需要在内存管理和地址映射上进行更多配置,而 RPC 实现较为简单,通常基于现有的网络通信库。前者适合分布式存储系统、高性能计算、内存数据库等需要快速访问远程内存的应用,后者适用于分布式系统中的远程服务调用,如微服务架构、远程文件系统操作等。
ODP MR | 按需分页内存区域
ODP MR:On-Demand Paging Memory-Region
前置知识:Demand Paging
Demand Paging 是一种虚拟内存管理技术,它允许程序的一部分或全部被加载到物理内存中,而不是一次性将所有内容都加载进来。 当程序访问未加载到内存的页面时,操作系统会根据需要将相应的页面加载到内存中,从而满足程序的执行需求。
Workflow:更多细节详见标题链接
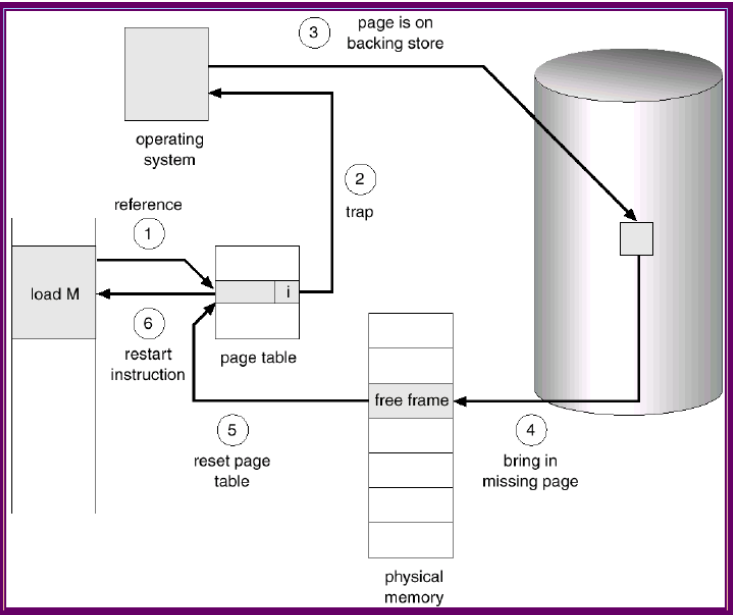
ODP MR Design
RNIC Page Table 允许 RNIC 在执行 RDMA 操作时绕过 CPU,直接访问物理内存。
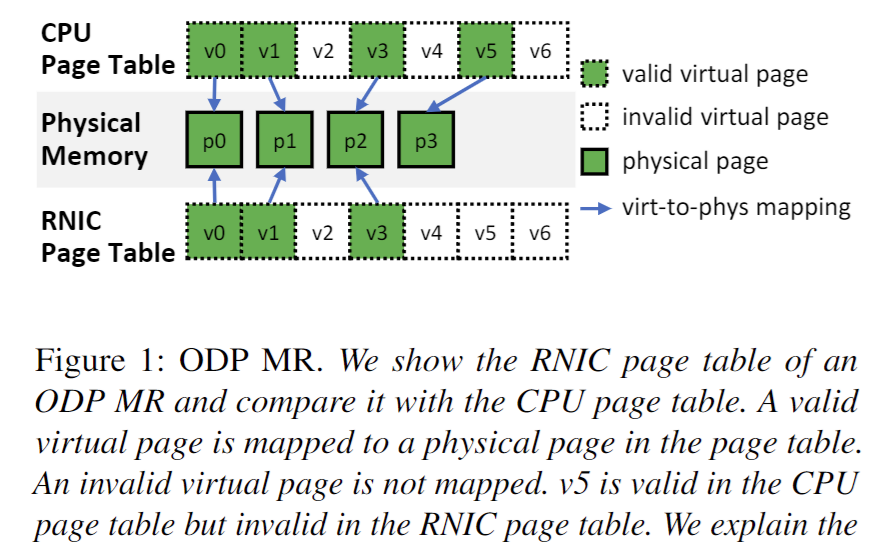
为了扩展RDMA连接的内存空间,ODP MR被提出。ODP MR允许应用程序在物理内存之上初始化一个更大的虚拟内存区域,并通过RDMA访问这些区域。
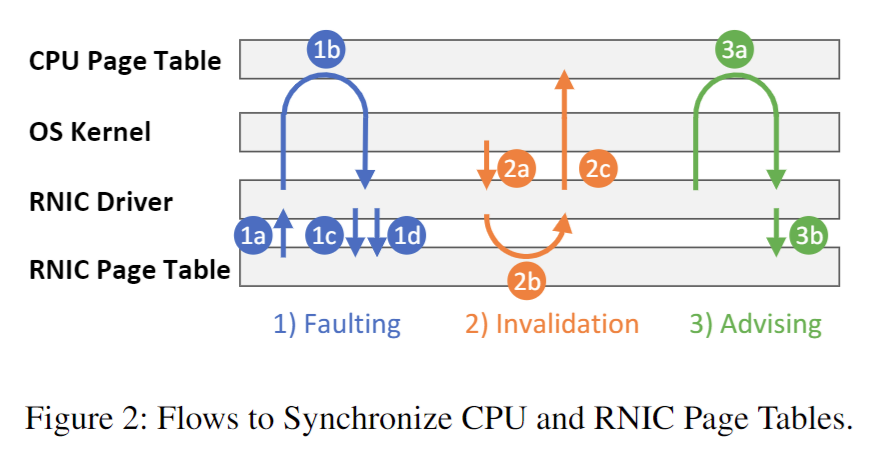
RNIC 页表将一些虚拟页面映射到物理页面(我们称之为有效虚拟页面),其余页面则保持未映射状态,即无效虚拟页面。由于页面不再固定(Pinned),因此操作系统内核可以交换和迁移页面。应用程序能够公开大于物理内存的 MR。由于虚拟到物理的映射可能会发生变化,CPU 和 RNIC 页表通过图 2 中所示的三个流程进行同步。
(1)Faulting
- 当 RDMA 请求访问无效虚拟页上的数据时,RNIC 暂停 QP(为了保持数据的一致性)并触发 RNIC 页面故障中断。
- 驱动程序通过
hmm_range_fault向操作系统内核请求虚拟到物理页的映射,操作系统内核在这些虚拟页上触发 CPU 页面故障,并在必要时填充页表。 - 驱动程序更新 RNIC 页表上的映射,并恢复 QP 的运行。
(2)Invalidation
- 当操作系统内核尝试在换页或页面迁移等场景中解除虚拟页的映射时,它会通过 mmu_interval_notifier 通知 RNIC 驱动程序使虚拟页失效。
- RNIC 驱动程序从 RNIC 页表中删除虚拟到物理的映射。
- 驱动程序通知操作系统内核,物理页不再被 RNIC 使用。然后,操作系统内核修改页表并重新使用这些物理页。
(3)Advising Flow
- 应用程序可以主动请求 RNIC 驱动程序在 RNIC 页表中填充一个范围。RNIC 驱动程序通过与失效处理类似的步骤来完成建议流程。
但是当RDMA请求访问到不在物理内存中的数据时,会触发一个RNIC页面错误,中断并通过CPU从SSD中加载数据到物理内存,并更新RNIC页表。实验数据显示,在处理一个ODP MR的RDMA读取请求时,当数据在内存中时,延迟仅为 3.66us,但当数据在SSD上时,延迟激增至 570.74 us。这个高延迟主要来源于RNIC页面错误处理的低效机制和CPU页面错误处理的高开销。
本文的动机
RNIC 在处理页面错误时会暂停QP,并通过CPU进行地址映射更新,这一过程耗时较长,导致高延迟。
CPU在处理页面错误时,需要从SSD中加载数据到物理内存,并更新RNIC页表,这一过程也同样耗时且难以扩展。

为了应对上述挑战,TeRM提出了一种高效的扩展RDMA连接内存的新方法,旨在通过将异常处理从硬件转移到软件中来优化性能,并引入了一系列技术以减少网络流量和CPU开销。
基于以上分析,TeRM 的设计基于以下两个主要原则:
- 原则一:将异常处理从硬件转移到软件: 由于RNIC硬件资源有限且处理异常路径的效率低,TeRM建议将RNIC页面错误的处理从硬件转移到软件中,利用软件的灵活性和高效性来处理异常情况。
- 原则二:消除关键路径中的CPU页面错误: CPU页面错误处理开销高且难以扩展,TeRM通过避免在关键路径中触发CPU页面错误,提升整体性能。
TeRM Design
Architecture|Workflow
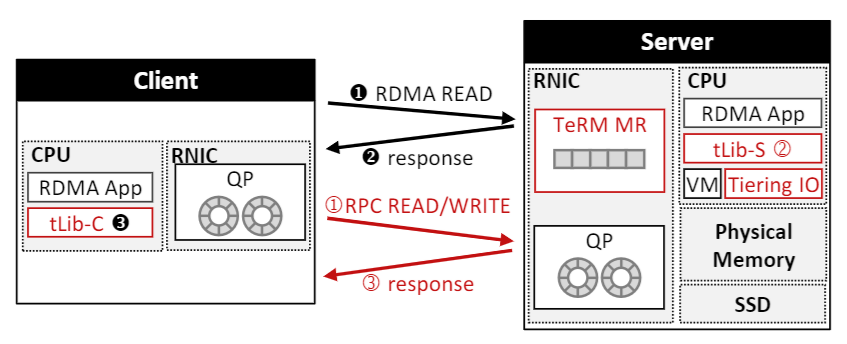
集群基础设施:集群由多台服务器和客户端机器组成,配备 RNIC 并通过 RDMA 网络连接。服务器通过 mmap 将 SSD 扩展为虚拟内存区域,并注册为 TeRM MR(内存区域),TeRM 利用 Linux 内核进行物理内存和 SSD 之间的按需分页管理。
tLib用户空间库:TeRM 包括两个用户空间库实例:
- tLib-S [服务器端]:管理 RNIC 页表并处里 RPC 请求
- tLib-C [客户端]:处理客户端发起的 RDMA 读取和写入
拥有多个 clinet 和 server
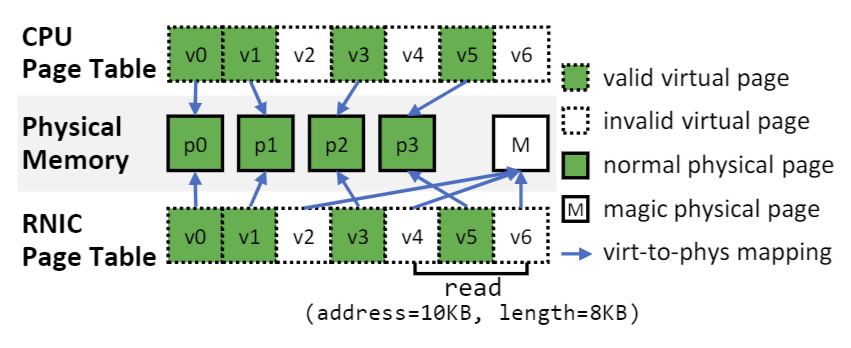
主要技术:
消除 RNIC 页面错误
- TeRM 通过预留一个物理页并用魔术模式填充,使得所有无效虚拟页都映射到该物理页,从而避免了 RNIC 页面错误。
- 比如,当碰到 invalid virtual page (比如 v2 v4 v6) 就将它们映射到一个 magic physical page (M),这样 RDMA READ 就不会触发 RNIC page fault.
自动预取机制
- TeRM 通过无锁读取协议和
dry run模式,提前计算事务的读写集,并在锁争用期间预取所需数据,减少从慢速存储读取数据的时间。
在计算机术语中,
dry run表示:显示运行的结果,但实际上并没有做出任何变更。- TeRM 通过无锁读取协议和
分层 I/O:使用文件 I/O 接口 (buffer I/O 和 direct I/O) 访问 SSD 扩展的虚拟内存,避免了 CPU 页面错误的高开销。
- buffer I/O:访问缓存数据
- direct I/O:直接访问 SSD 数据
热点数据提升:通过客户端跟踪和服务器累积访问频率,确定并动态提升热点数据,将其从 SSD 提升到物理内存,从而提高整体性能。
本文由 Yikun Wu 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。




