
Paper: SMART: A High-Performance Adaptive Radix Tree for Disaggregated Memory
Slide: View the slides
Background
随着计算和存储资源需求的不断增长,分离式内存(Disaggregated Memory, DM)架构逐渐成为高效资源管理的解决方案。DM 将计算资源和存储资源分离到独立的资源池中,并通过高速 RDMA 网络进行互连。该架构能够提高资源利用率,并为分布式计算提供更高的可扩展性。然而,由于计算节点(CN)和内存节点(MN)之间的远程访问开销,DM 面临新的挑战,其中之一就是 索引结构的优化。
RDMA Architecture
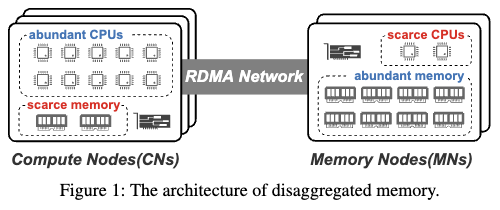
现有的 DM 范围索引通常基于 B+ 树,这种传统的树索引结构在 DM 环境下存在严重的读放大(Read Amplification)和写放大(Write Amplification)问题。当在 B+ 树中查找或插入键值对时,需要遍历多个内部节点,每个节点中包含许多无关的键和指针,从而增加了不必要的网络带宽消耗。由于 DM 的主要瓶颈是网络带宽,B+ 树的读写放大会迅速耗尽 RDMA 网络带宽,导致索引查询的吞吐量降低和访问延迟升高。例如,最先进的 DM B+ 树索引 Sherman 由于这些问题,其吞吐量比 RNIC(远程网络接口卡)的理论上限低 10.8 倍。
Sherman is the state-of-the-art B+ tree on DM
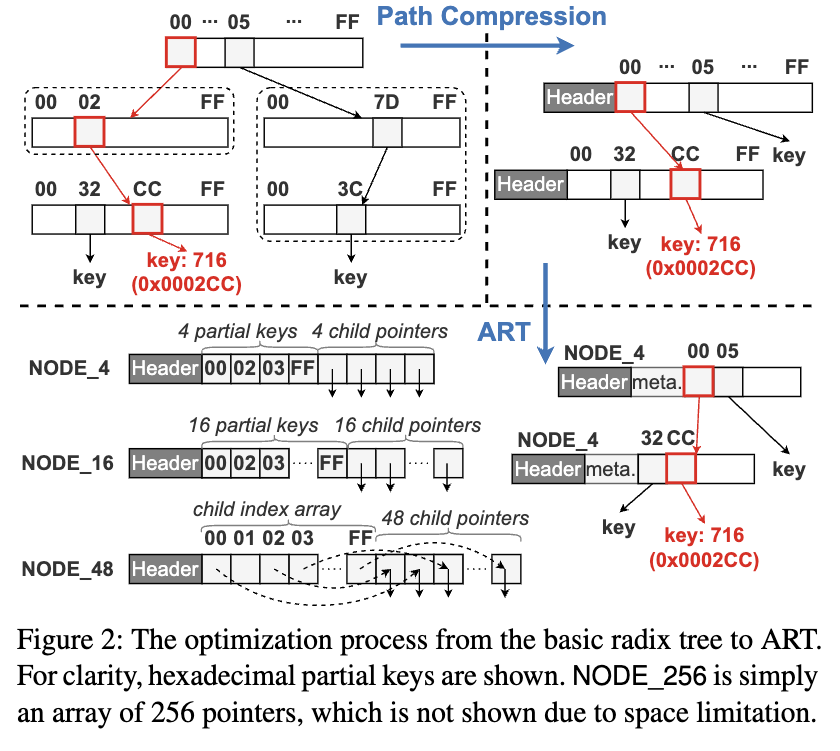
针对这一问题,自适应基数树(Adaptive Radix Tree, ART) 作为替代方案进入研究视野。与 B+ 树相比,ART 在内部节点中不存储完整的键,而是使用部分键(partial keys)进行索引,从而减少了读放大和写放大。然而,ART 直接应用于 DM 仍然存在多个挑战,包括昂贵的锁机制、冗余的 I/O 操作,以及复杂的计算侧缓存一致性验证。
Motivation
B+ 树在 DM 环境下的主要性能瓶颈在于高读放大和写放大,这些放大会加重 RDMA 网络的负担,降低索引的整体性能。
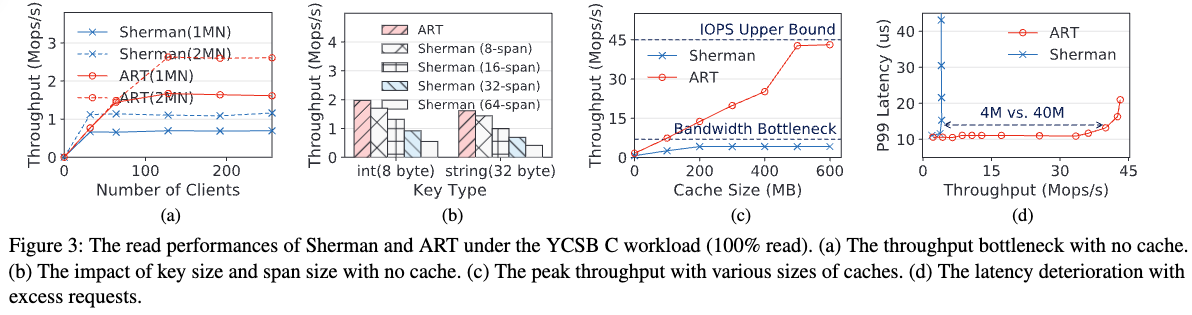
相比之下,ART 由于其更紧凑的数据结构,本质上具有更低的读写放大,因此在 DM 中具有潜在的优势。通过理论分析和实验结果,我们得出以下观察结论:
- B+ 树在 DM 中的读写放大严重影响吞吐量
- B+ 树在内部节点存储完整的键,并且叶子节点存储多个键值对。在每次索引操作时,都需要读取整个叶子节点,从而导致严重的带宽消耗。
- 例如,在 Sherman 方案中,每次读取单个键值对需要额外读取 33 倍的数据,而 ART 仅需 1.1 倍。
- B+ 树的吞吐量受限于网络带宽
- DM 的瓶颈通常是 RDMA 网络带宽,而 B+ 树的读写放大使得其带宽消耗远超 ART,从而导致吞吐量受限。
- 例如,在 YCSB C(100% 读)负载下【如图】,Sherman 受限于网络带宽的峰值吞吐量为 4.17 Mops/s,而 ART 的吞吐量可达 45 Mops/s,完全利用了 RNIC 的 IOPS 上限。
- B+ 树的锁竞争和远程锁操作增加了写入延迟
- 由于 DM 的远程内存访问开销较大,传统的基于锁的并发控制会导致频繁的 RDMA 重试,增加网络延迟。
- 在 YCSB A(50% 读 + 50% 更新)负载下,Sherman 由于锁冲突导致吞吐量下降 7.4 倍,而 ART 由于采用读优化写排除(ROWEX)协议,性能更优。
ART 仍然面临多项挑战:
- 锁机制开销高:ART 采用的 ROWEX 并发控制仍然包含许多远程锁操作,导致写入性能下降。
- 冗余 I/O 操作降低 IOPS:在多个计算节点上运行的客户端会产生重复的 RDMA 读写操作,浪费有限的 IOPS 资源。
- 计算侧缓存一致性验证复杂:ART 的路径压缩(Path Compression)和自适应节点设计导致频繁的地址变更,使得计算节点的缓存无效化问题更加复杂。
基于这些挑战,本文提出了一种高性能的分离式内存自适应基数树(SMART),它通过以下几种机制优化 ART 在 DM 上的表现。
- 混合并发控制
- 读代理与写合并(RDWC)
- 反向检查机制
Design
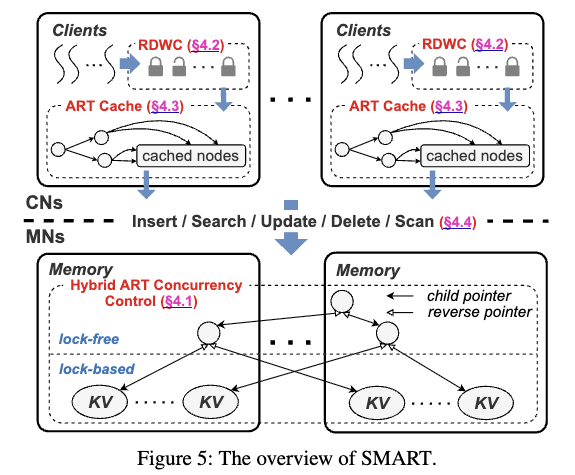
SMART 主要通过三种关键技术来提升 ART 在 DM 环境下的性能。
混合并发控制(Hybrid Concurrency Control)
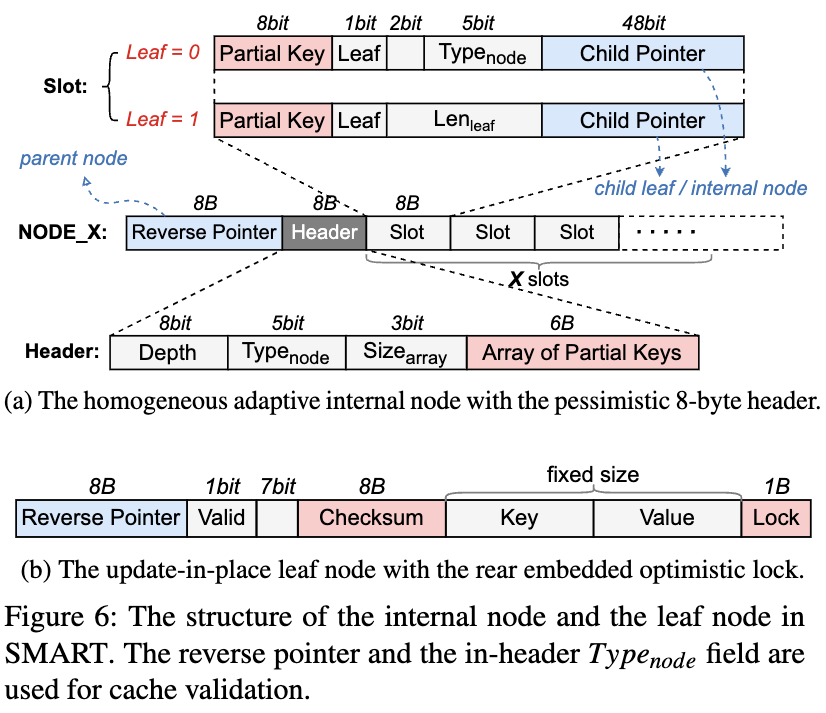
internal node & leaf node
insert worflow —— SMART
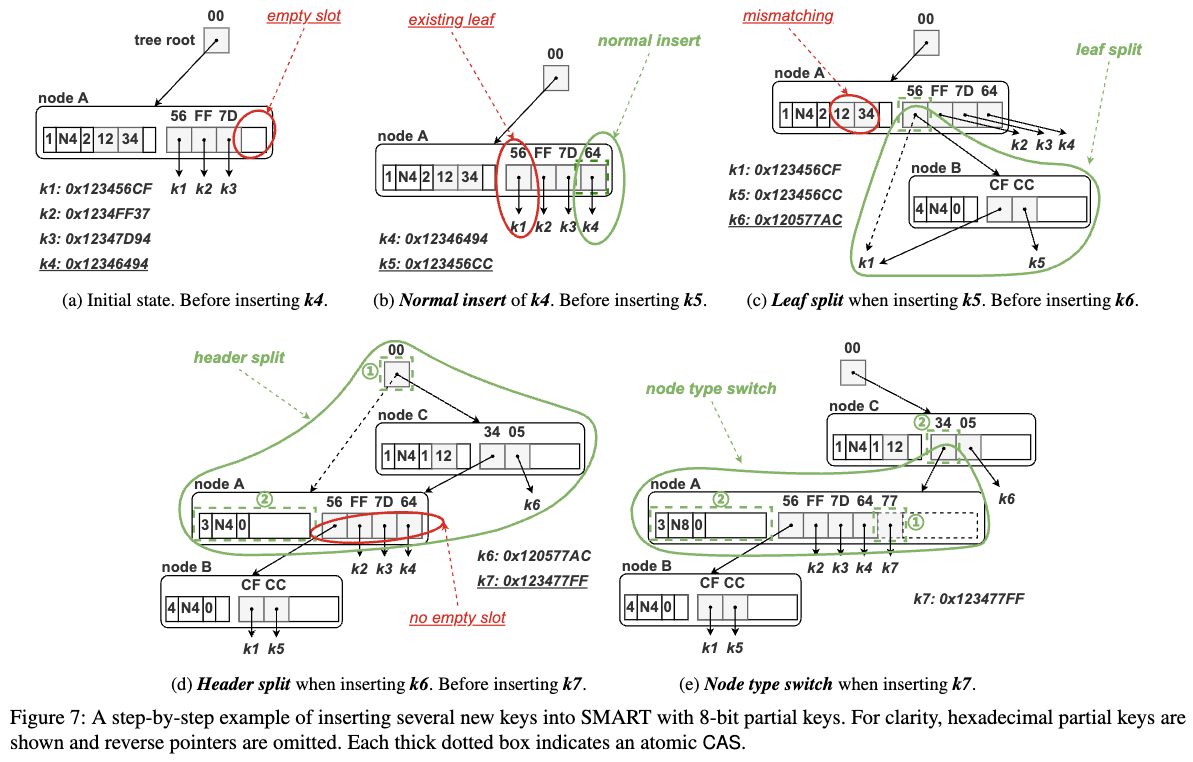
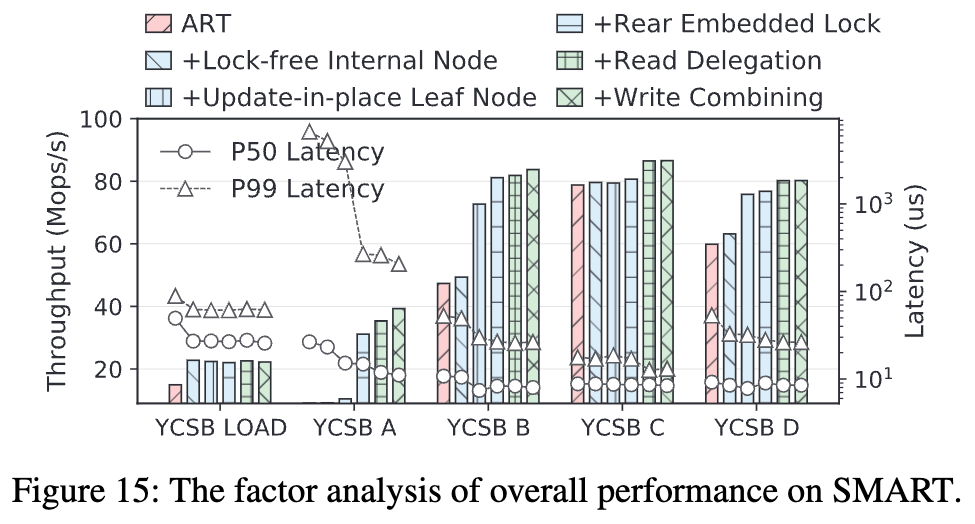
- 针对 ART 锁机制昂贵 的问题,SMART 采用锁自由(lock-free)内部节点和细粒度锁(fine-grained locks)叶子节点的设计。
- 内部节点使用 无锁结构,避免频繁的 RDMA 比较和交换(CAS)操作,同时提升并发性能。
- 叶子节点仍然使用锁,但采用嵌入式锁(embedded locks),减少锁释放的开销,使得锁操作与数据写入同时完成,提高吞吐量。
读代理与写合并(Read Delegation and Write Combining, RDWC)
RDWC
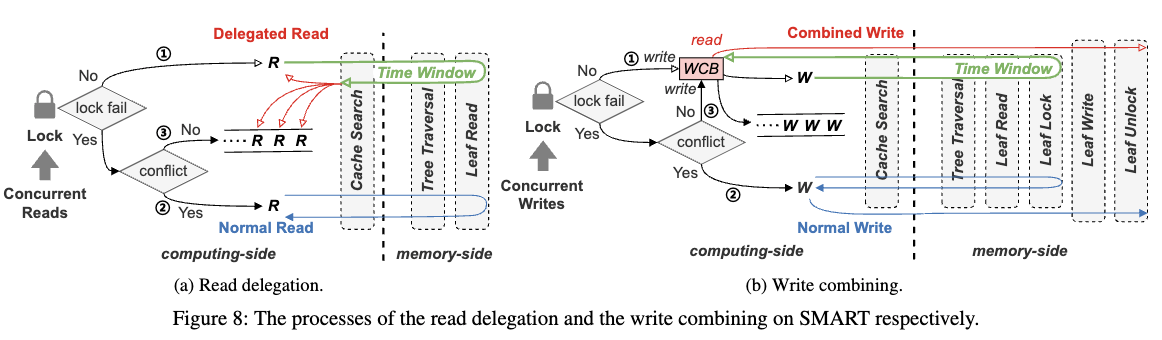
针对冗余 I/O 操作降低 IOPS 的问题,SMART 采用 RDWC 技术:
- 读代理(Read Delegation):多个客户端在同一计算节点访问相同键时,仅有一个客户端执行 RDMA 读取,并将结果共享给其他客户端,从而减少重复的 RDMA 读取操作。
- 写合并(Write Combining):多个客户端写入相同键时,先在计算节点合并写入请求,然后一次性将合并后的数据写入远程内存,减少 RDMA 写入次数,提高写吞吐量。
反向检查机制(Reverse Check Mechanism)
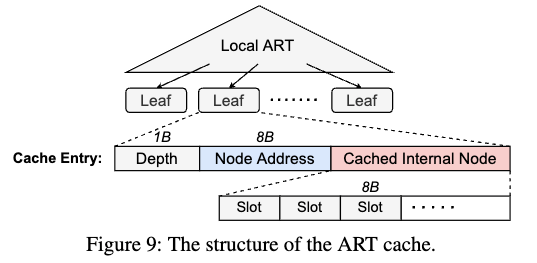

针对缓存一致性验证复杂的问题,SMART 设计了一种反向检查机制:
- 在每个 ART 节点中存储反向指针(Reverse Pointer),指向其父节点,使得计算节点可以验证缓存数据是否过期。
- 在每个节点头部存储类型字段(Typenode Field),如果节点类型发生变化(如路径压缩导致的节点类型变化),计算节点可以通过该字段检查缓存是否需要刷新。
Evaluation
SMART 通过实验对比了现有的 B+ 树索引 Sherman 和传统 ART 在 DM 上的性能。实验环境包括 16 个计算节点和 2 个内存节点,采用 100Gbps RDMA 网络,并运行 YCSB 负载。
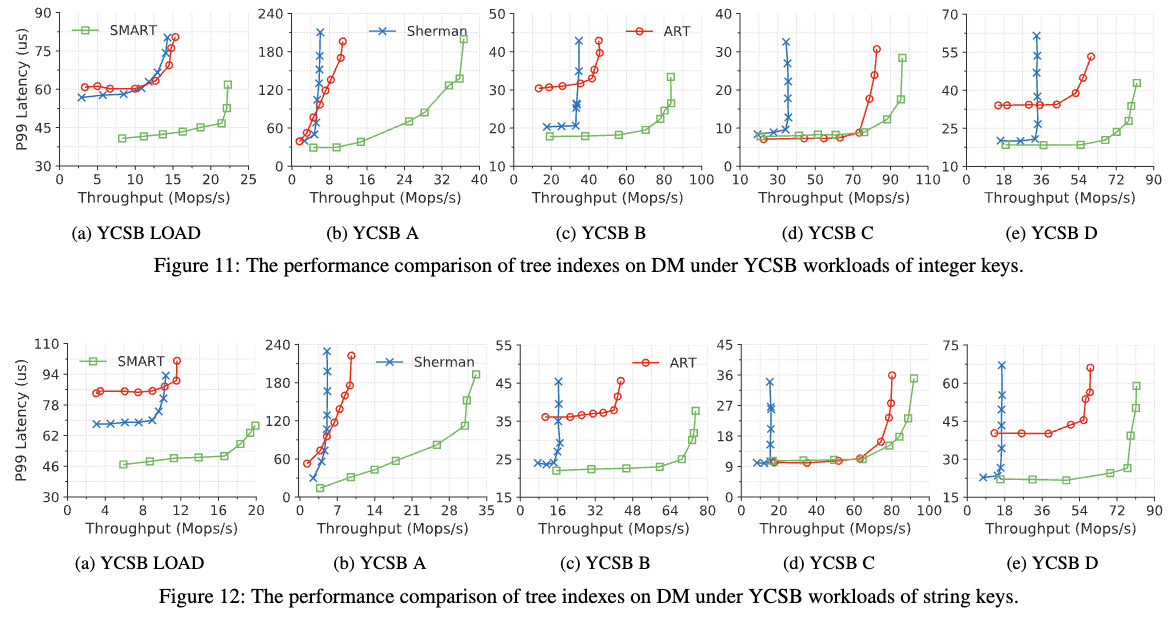
实验结果表明:
- 在写密集型负载(YCSB A)下,SMART 的吞吐量比 Sherman 高 6.1 倍,比 ART 高 3.4 倍,同时 P99 延迟分别降低 1.4 倍和 1.3 倍。
- 在只读负载(YCSB C)下,SMART 吞吐量比 Sherman 高 2.8 倍,比 ART 高 1.2 倍,同时保持相似的 P99 延迟。
- 在混合负载(YCSB B)下,SMART 吞吐量比 Sherman 高 2.4 倍,比 ART 高 1.8 倍,同时 P99 延迟降低 1.1 倍和 1.7 倍。
- 在高并发环境下(>800 clients),ART 由于缓存失效和锁冲突,性能下降明显,而 SMART 保持优异的可扩展性。
本文由 Yikun Wu 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。




