
Paper: A Tale of Two Paths: Toward a Hybrid Data Plane for Efficient Far-Memory Applications
Slide: View the slides
Background
随着网络硬件的快速发展,远程内存(Far Memory)技术因其能够突破本地内存容量限制而受到广泛关注。当前的远程内存系统大致分为两种数据路径:
- 基于内核分页系统的页粒度访问路径和绕过内核(Kernel-based page-level profiling)
- 基于对象粒度的访问路径(object fetching)
对象粒度访问通常性能更优,但对计算资源的需求显著更高。
Object fetching is motivated by two observations on the inefficiencies of paging.
- First, fetching data at the page granularity often leads to I/O amplification.
- Second, managing data in the kernel space is agnostic to program semantics, resulting in missed optimization opportunities.

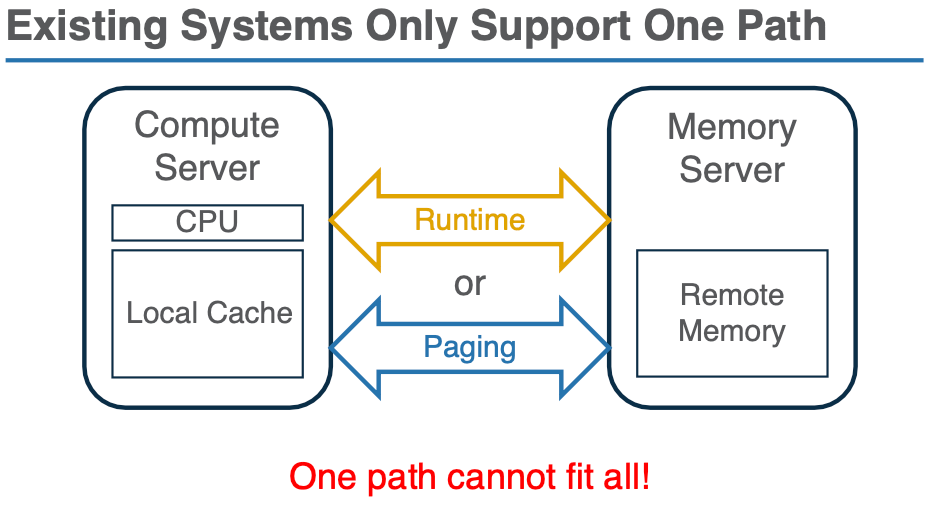
分页系统(Paging):一种使用内核的虚拟内存分页机制来透明地访问远程内存的方法。例如,InfiniSwap、Fastswap 和 Canvas 等技术使用内核的分页系统,通过交换远程和本地内存的页面来提高应用程序的内存容量。分页适用于数据访问模式较为规则(如顺序访问)的工作负载。
- 优点:对于顺序或有规律的内存访问模式,分页能够减少 I/O 放大,提升性能。
- 缺点:当应用程序的访问模式不规则时,分页会导致大量不必要的数据交换,进而产生I/O放大(I/O Amplification),即加载的大部分页面都包含无用数据,浪费了大量的内存带宽和计算资源。
对象粒度访问(Object Fetching):与页粒度的方式相比,对象粒度访问使用应用程序的抽象(即对象)来管理远程内存。这种方式可以更精确地获取所需数据,减少 I/O 放大。
- 优点:通过对象粒度交换数据,能够避免加载不相关的内存数据,从而显著减少 I/O 开销,提升效率。
- 缺点:对象粒度的管理需要更多的计算资源,例如,运行对象粒度的最近最少使用(LRU)算法和逐出(Eviction)操作需要大量的计算能力。
Challenges
Major insight:我们能否为应用程序启用始终在线的分析来识别其访问模式,并在分页和对象获取之间动态切换以适应观察到的模式?如果有效实施,这种方法与最先进的技术相比有两个优势。
- 首先,即使程序输入不断变化,它的连续分析也可以动态识别不同计算阶段或访问不同数据结构的并行线程的模式。因此,它可以快速更改访问路径以使用更高效的获取机制。
- 其次,对于具有不规则模式的程序,对象获取会将访问时间接近的对象移动到连续的内存空间中,从而在程序执行时动态改善局部性。这使得执行越来越适合分页,从而具有更高的资源效率
Although promising, realizing this insight requires overcoming three major challenges, as elaborated below:
1. 挑战:如何在低开销下持续精确地对应用进行剖析
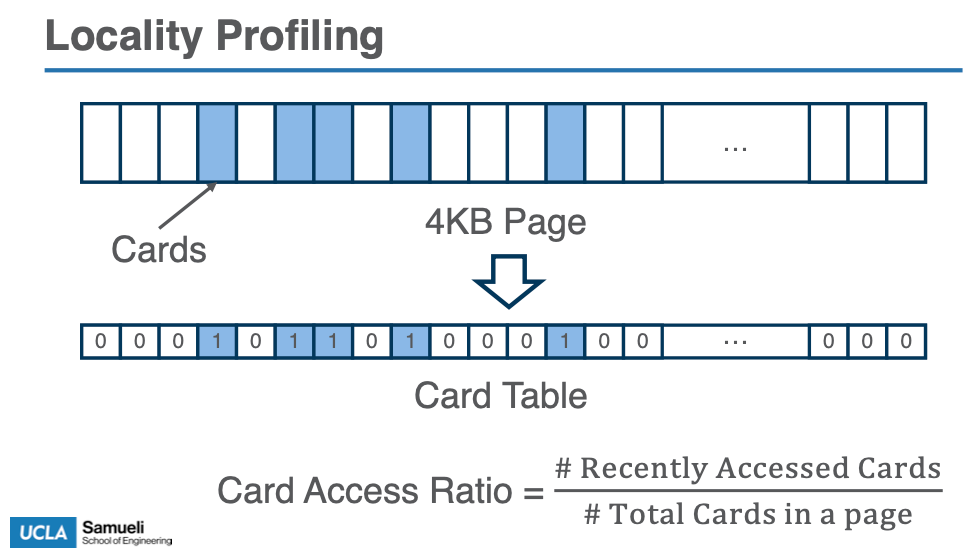
传统的内核级分页系统无法提供足够细粒度的数据局部性信息。例如,如果一个页面上的单个对象被频繁访问,而其他对象没有被访问,内核分页系统仍然会将整个页面视为“热点页面”,这导致对不必要的数据进行交换,从而产生 I/O 放大。
- 使用卡片访问表(CAT):Atlas 通过将每个页面划分为多个卡片,每个卡片代表页面上的 16 字节数据,以便精确测量数据局部性。每当一个页面被访问时,Atlas 会更新对应卡片的访问标记,从而能够更细粒度地分析页面访问的局部性。
- 页面的卡片访问率(CAR):通过卡片访问表计算页面的卡片访问率(CAR),如果页面的 CAR 值较高,说明该页面有较好的局部性,可以通过分页机制进行访问;如果 CAR 值较低,则使用对象访问路径来减少 I/O 放大。
2. 挑战:如何动态切换访问机制
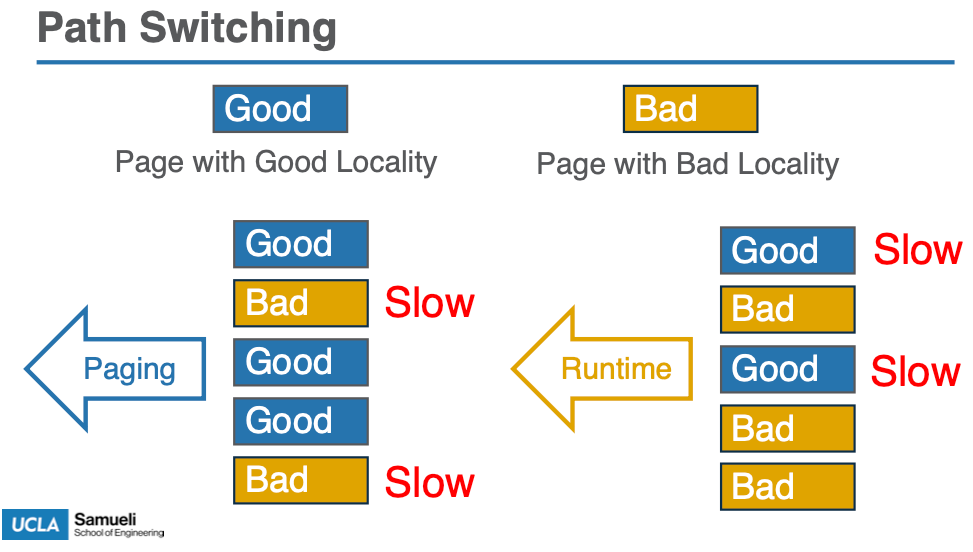
对于不同的工作负载,局部性会发生变化,因此需要动态切换访问机制。例如,在工作负载初期可能是随机访问模式,稍后可能转为顺序访问,最优的访问路径可能发生变化。
- 使用页面选择标志(PSF):Atlas 为每个页面维护一个 1-bit 的标志(PSF),用于指示该页面是通过 “runtime” 还是 “paging” 访问。当页面被交换时,PSF 的值会根据页面的局部性(由 CAR 值决定)动态更新。如果页面的 CAR 值较低,则选择 runtime(对象粒度访问);如果较高,则选择 paging(页粒度访问)。
- 动态切换:通过分析程序的访问模式,Atlas 能够在执行过程中实时选择合适的访问路径。这种动态切换确保了系统能够在不同的计算阶段或并行线程之间优化内存访问模式。
- 为了减少死对象造成的碎片,Atlas 会运行并发撤离任务,定期将活动对象移至连续的内存空间。每次撤离期间,Atlas 都会将最近访问的对象分组到连续的页面中,以进一步改善数据局部性。
3. 挑战:如何协调两条访问路径的同步
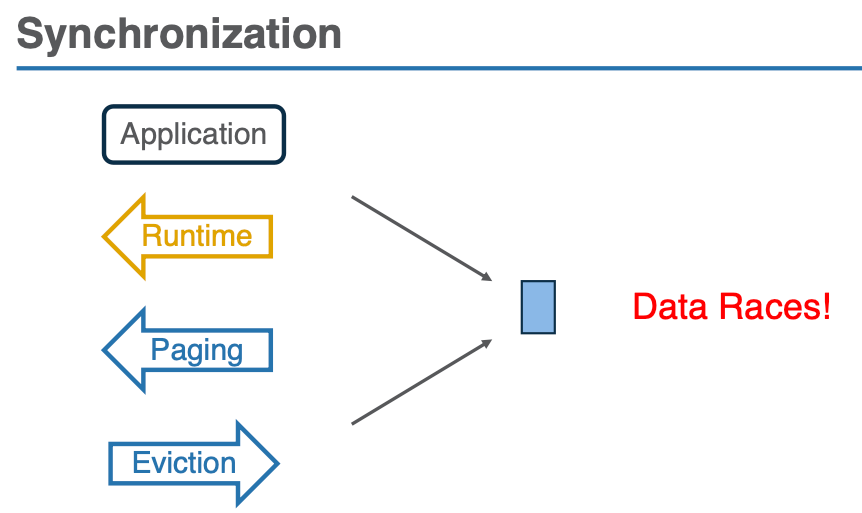
由于 kernel 和 runtime 系统是独立的,它们之间没有直接的协调机制,因此可能会发生并发的访问冲突。例如,一个页面可能正在进行分页操作,而同时另一个线程可能在运行时路径中对同一页面进行对象访问,这样会产生数据一致性问题。
- 同步协议:为了解决这种同步问题,Atlas 设计了一种同步协议,确保内核分页和运行时对象访问之间的一致性。具体来说,Atlas 保证:
- 对象-页面冲突:禁止同一页面在不同的访问路径下同时被访问。只有当页面的 PSF 值被更新时,才会切换访问路径。
- 页面交换与对象交换冲突:如果一个页面包含某个正在使用的对象(例如,在一个活跃的解引用范围内),该页面不能被交换出去。
- 对象迁移与垃圾回收冲突:在执行对象迁移时,必须确保对象不会在迁移过程中被其他线程的解引用操作访问。
- 使用智能指针与解引用范围:Atlas 使用类似 C++ 智能指针的机制(例如
AtlasUniquePtr),通过为每个对象定义解引用范围,确保在对象迁移或交换期间,其指针不会被错误地更新或访问。这样可以确保数据一致性。
Motivation🔥
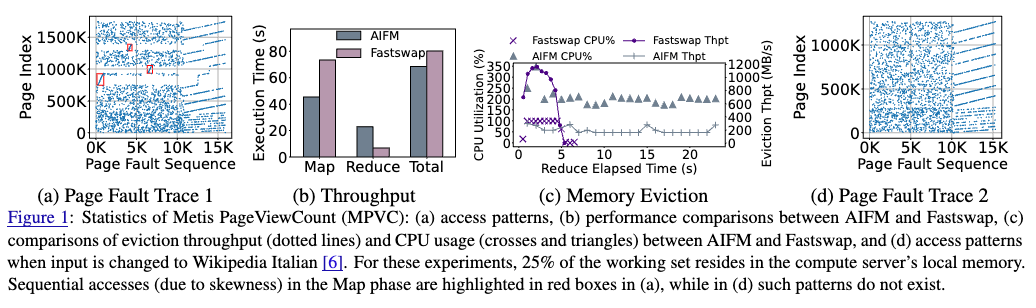
多样化的内存访问模式:许多真实的云应用展示了复杂的内存访问模式,这些模式可能是顺序的、随机的、或是其他混合类型。随着应用的执行,这些访问模式可能会发生变化。例如,某些程序的访问模式可能在某个计算阶段表现出规律性,而在另一个阶段则可能变得不规则。在应用 Metis(一个优化的 MapReduce 框架)中,Page View Count (PVC) 程序在 “Map” 阶段会呈现出部分顺序的访问模式(由于数据的偏斜),而在 “Reduce” 阶段则呈现出清晰的顺序访问模式。
现有的解决方案(如 AIFM)采用对象粒度访问来减少I/O放大,但它的高计算开销使得它在某些场景下不适用。而传统的分页方法则因为局部性差导致的I/O放大问题而变得低效。
问题的核心:究竟如何在不同的工作负载和计算阶段之间选择合适的内存访问路径,以便在减少I/O放大的同时不增加不必要的计算开销?
动态路径切换的需求:由于程序的内存访问模式在执行过程中是不断变化的,无法仅仅依靠静态的编译时分析(如 Mira 等技术)来选择访问路径。因此,需要一种能够在程序执行过程中持续监测其内存访问模式,并根据实际访问模式动态切换访问路径的方法。
混合数据平面(Hybrid Data Plane):根据应用的内存访问模式,动态选择使用分页(对于具有良好局部性的应用)或对象粒度访问(对于具有不规则访问模式的应用)。这种方式的优势在于能够在不同的计算阶段和并行线程之间自动调整内存访问机制,从而提高远程内存的效率。
离线分析技术(如 Mira):尽管有一些编译器技术(如 Mira)尝试通过离线分析来优化内存访问路径,但它们依赖于程序的输入数据和执行阶段的静态分析。对于交互式应用(如 Memcached 和 WebService),其输入数据和工作负载不断变化,离线分析无法适应这些变化。
Design
Atlas leaverage the runtime to compute a card access table (CAT) for each page, which is a bitmap where each bit corresponds to a card (i.e., consecutive 16 bytes)
利用 card access rate (CAR) 作为评判 page 的良好/较差局部性,方便后续的转换
A page with a high card access rate (CAR, measured as the percentage of the set bits in its CAT) is deemed to possess good locality and should be accessed with paging, while a page with a low CAR has poor locality and should be accessed with object fetching.
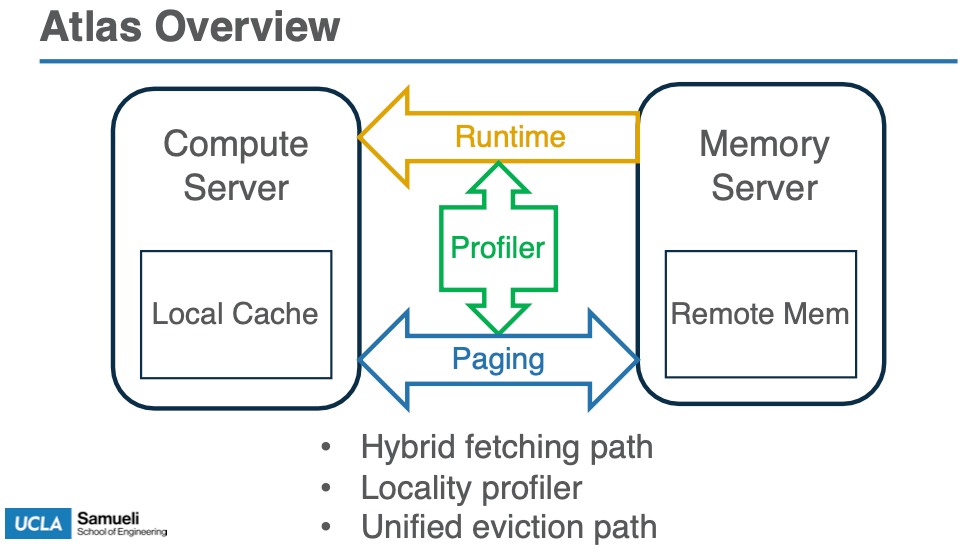
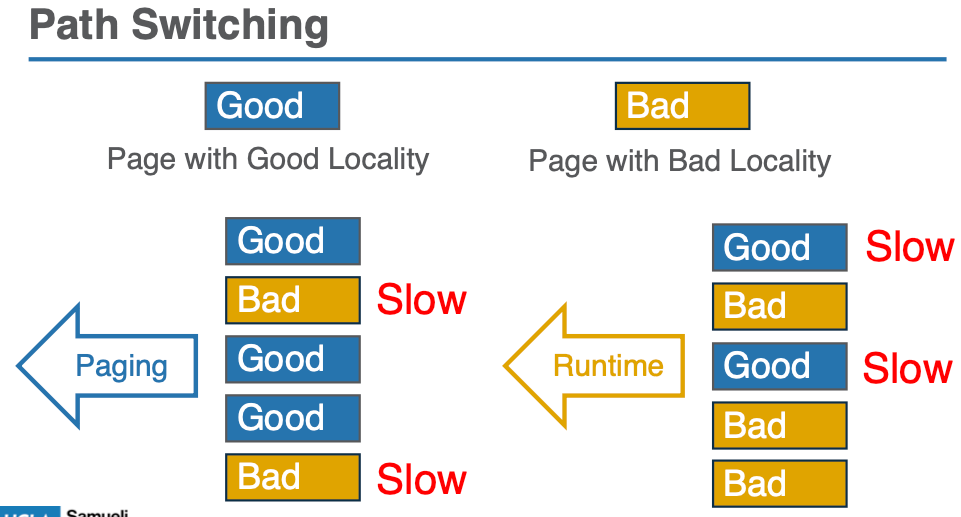
主要机制:
- 引入卡片(card)作为页面内的局部性度量单位,通过对页面访问的细粒度分析进行动态优化。
- 使用页面选择标志(Path Selector Flag, PSF)动态决定每个页面的访问路径。
- 数据的迁出和迁入在页面粒度完成,避免高计算开销的对象逐出操作。
运行时与内核的同步:
- 提出了一个同步协议,确保分页路径和对象路径之间的访问一致性。
Evaluation
1️⃣ 硬件和软件环境
- 硬件
- 计算服务器和内存服务器:每个服务器使用 2 个 Intel Xeon Gold 6342 CPUs(每个CPU 24个物理核心),每台服务器有 256GB 内存,以及 100Gbps 的 Mellanox ConnectX-5 InfiniBand 网络适配器。
- 两台服务器通过 200 Gbps InfiniBand 交换机连接。
- 操作系统:Ubuntu 18.04,内核版本为 5.14-rc5。
- 配置
- 禁用 Turbo Boost、CPU频率调节 和 透明大页,以减少硬件特性对结果的影响。
- 实验框架
- Atlas:包括对运行时库和 Linux 内核进行修改,添加页面管理任务(例如路径同步)等。
- 使用 AIFM 和 Fastswap 作为对比基准。
2️⃣ 基准应用程序
为了评估 Atlas 在不同场景下的性能,作者选择了 8 个应用程序,覆盖了不同的内存访问模式和计算需求:
- Memcached:一个内存键值存储系统,使用了两种不同的工作负载(MCD-CL 来自 Meta 的 CacheLib,和 MCD-U 来自 YCSB)。
- GraphOne:一个实时图分析数据库,支持图的增量更新。
- Aspen:一个纯函数式树形图处理框架,处理动态变化的图。
- Metis:一个数据处理框架,支持不同的 MapReduce 类型操作(MWC 和 MPVC)。
- DataFrame:一个表格数据结构,类似 Pandas 用于内存数据处理。
- WebService:一个用于模拟分布式负载的交互式服务。
这些应用程序的内存访问模式涵盖了顺序访问、随机访问、混合访问等不同模式,能够全面展示 Atlas 在各种场景下的表现。
3️⃣ 本地内存比例:为了评估 Atlas 在不同远程内存配置下的表现,实验使用了五种不同的本地内存配置,分别为:
- 13%、25%、50%、75%、100% 本地内存比例。
- 其中,100% 本地内存的配置用于评估 Atlas 和其他系统的运行时开销(如智能指针解引用、预取记录和垃圾回收等)。
4️⃣ 计算资源配置:所有实验使用多线程并行执行,确保可以评估在高并发下 Atlas 的性能。
5️⃣ 评估指标
论文使用以下几个核心指标来评估 Atlas 的性能:
- 吞吐量:表示单位时间内处理的数据量,通常使用每秒完成的操作数(MOPS, Million Operations Per Second)来衡量。
- 延迟:评估请求的响应时间,特别关注尾延迟(tail latency),即高负载下的响应时间。
- 内存利用率:评估系统如何有效利用本地内存和远程内存,包括 I/O 放大的情况。
- CPU 利用率:衡量系统在进行内存管理和计算时的 CPU 使用情况,尤其是在高负载下的资源占用。
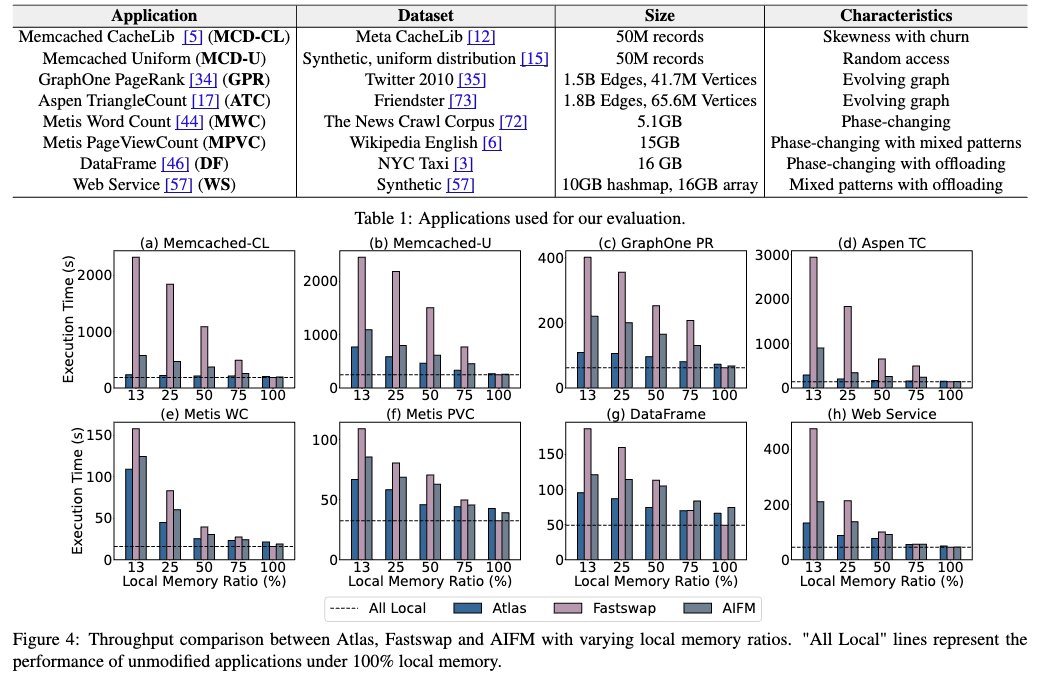
如图为 throughput
Thoughts
典型的 A + B 技术优化的论文,可以借鉴 A + B 的思路融合 fixed-size 和 variable-size 分块策略(我觉得这个可以作为另一个研究点):
no one fits all
- motivation1(先说说二者策略的优劣,通过实验分析,只用 fixed-size 和只用 variable-size 的方法测试)
- motivation2(负载存在大文件和小文件,有些文件长期不变,有些文件经常变化)
- IOPS 高的时候可以选择定长分块(速度快)
- 系统空闲可以选择变长分块(压缩率高)
本文由 Yikun Wu 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。




