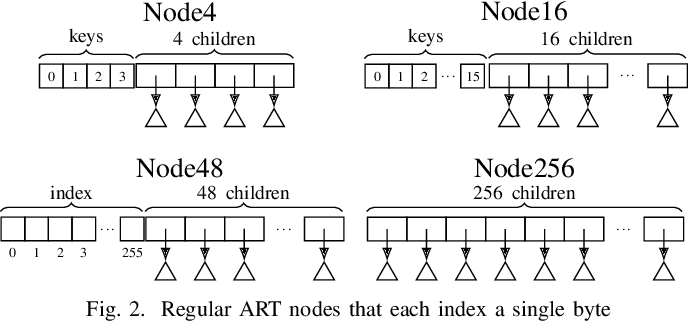
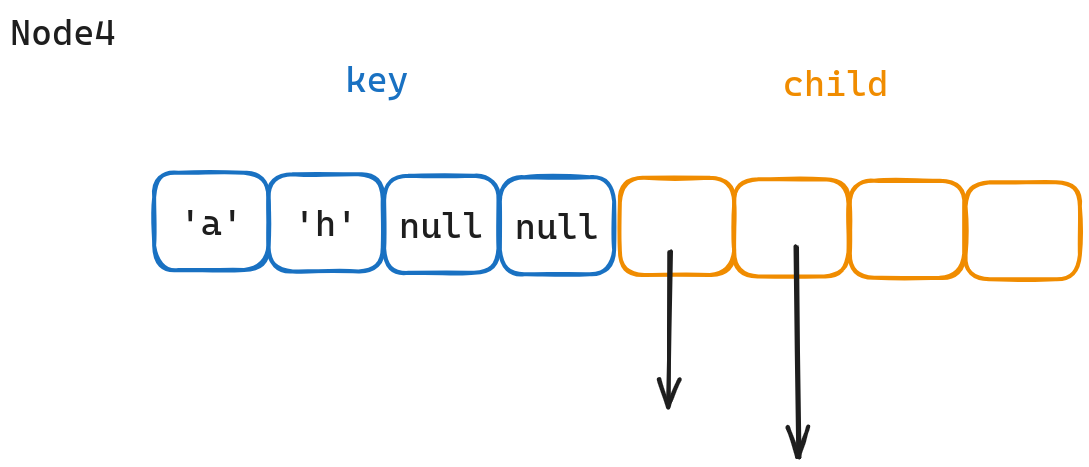
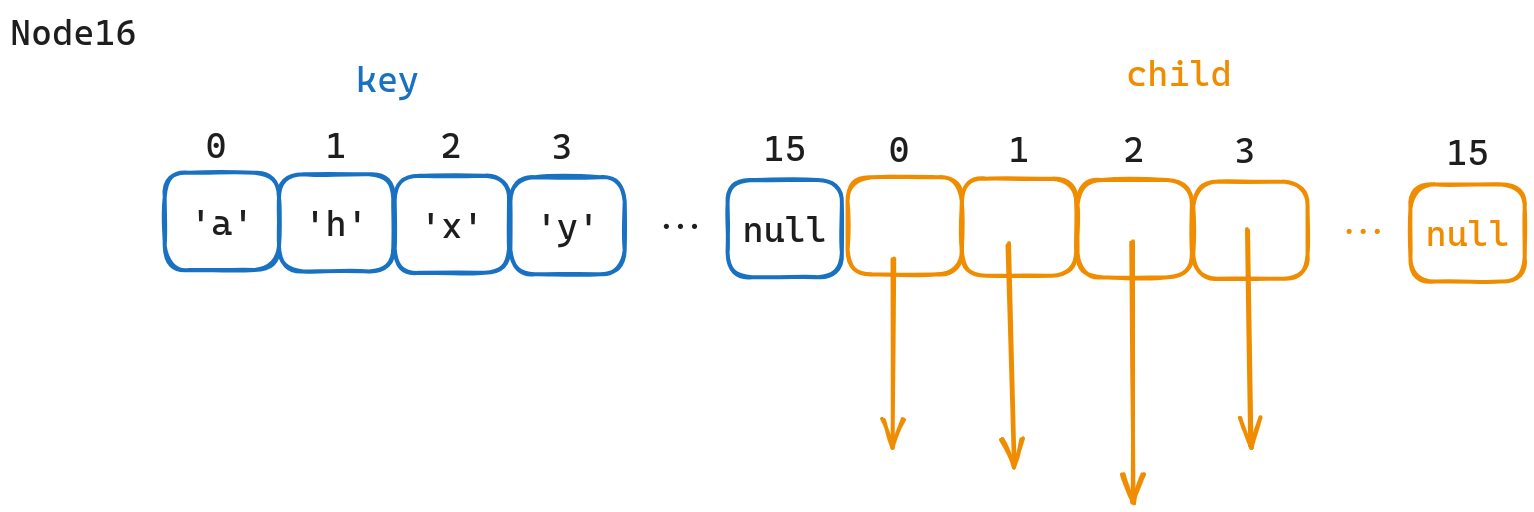
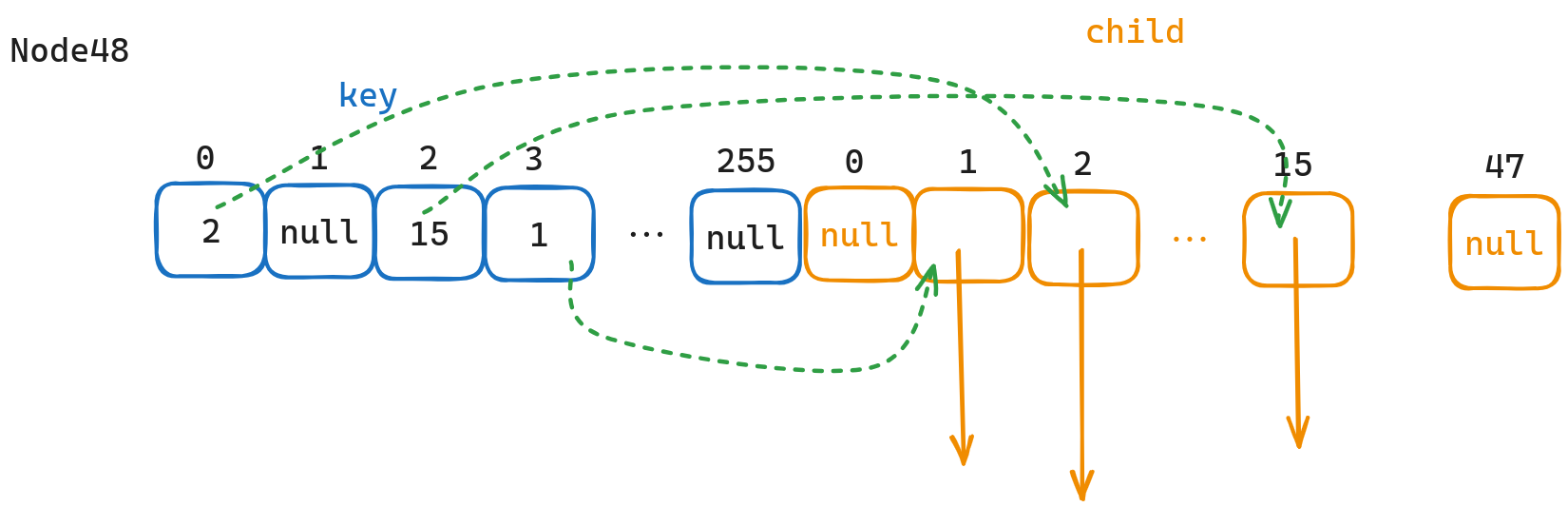
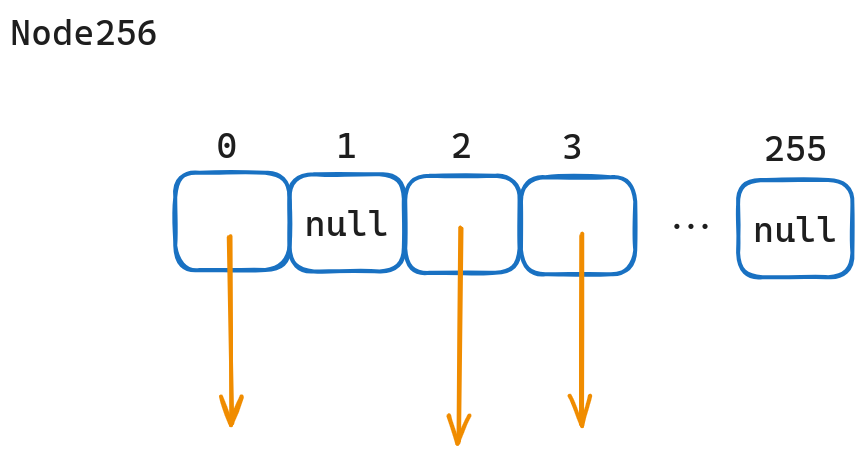
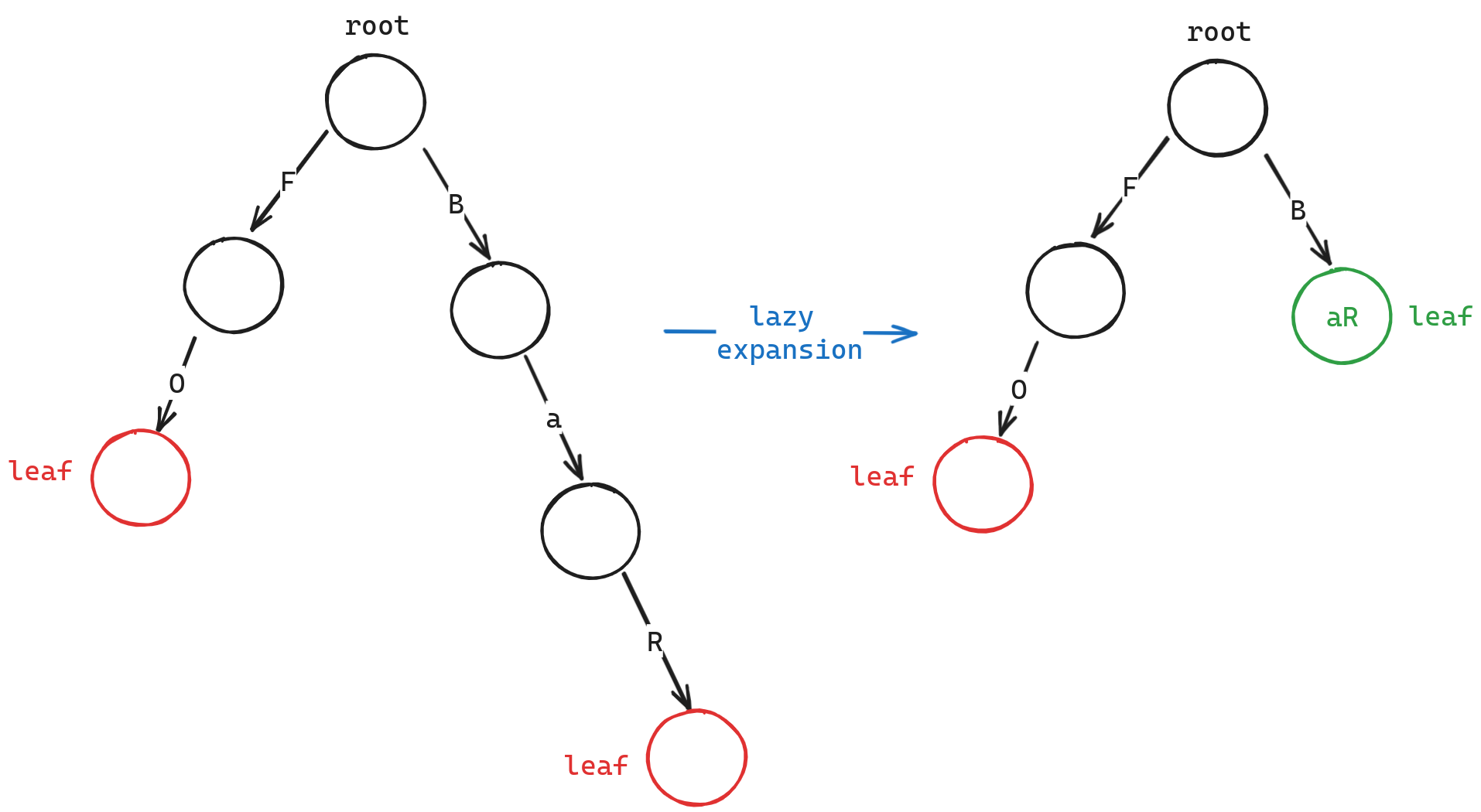
structNode { Node* son[26]{}; bool end = false; };
classTrie { private: Node* root = newNode();
intfind(string word){ Node* cur = root; for (char c : word) { c -= 'a'; if (cur->son[c] == nullptr) { return0; // not found } cur = cur->son[c]; } return cur->end ? 2 : 1; }
public: Trie() {}
voidinsert(string word){ Node* cur = root; for (char c : word) { c -= 'a'; if (cur->son[c] == nullptr) { cur->son[c] = newNode(); } cur = cur->son[c]; } cur->end = true; }
对于 ART 来说,前面介绍的都是对于字符串类型 string,如果作为一个广泛使用的索引,也需要支持不同类型的数据。而 ART 索引实际上是把 Key 作为数据流进行处理的,也就是说如果想要通过 ART 进行范围搜索,我们需要让 Key 保持一个性质,即二进制的大小与该类型的语义大小相同: $$ memcmp(binary(x),binary(y)) < 0 \Leftrightarrow x < y \ memcmp(binary(x),binary(y)) = 0 \Leftrightarrow x = y \ memcmp(binary(x),binary(y)) > 0 \Leftrightarrow x > y $$ 因此我们需要对某些数字进行转换。
if (!node.IsSet()) { // node is currently empty, create a leaf here with the key Leaf::New(*this, node, key, depth, row_id); returntrue; }
if (node.DecodeARTNodeType() == NType::LEAF) {
// add a row ID to a leaf, if they have the same key auto &leaf = Leaf::Get(*this, node); auto mismatch_position = leaf.prefix.KeyMismatchPosition(*this, key, depth);
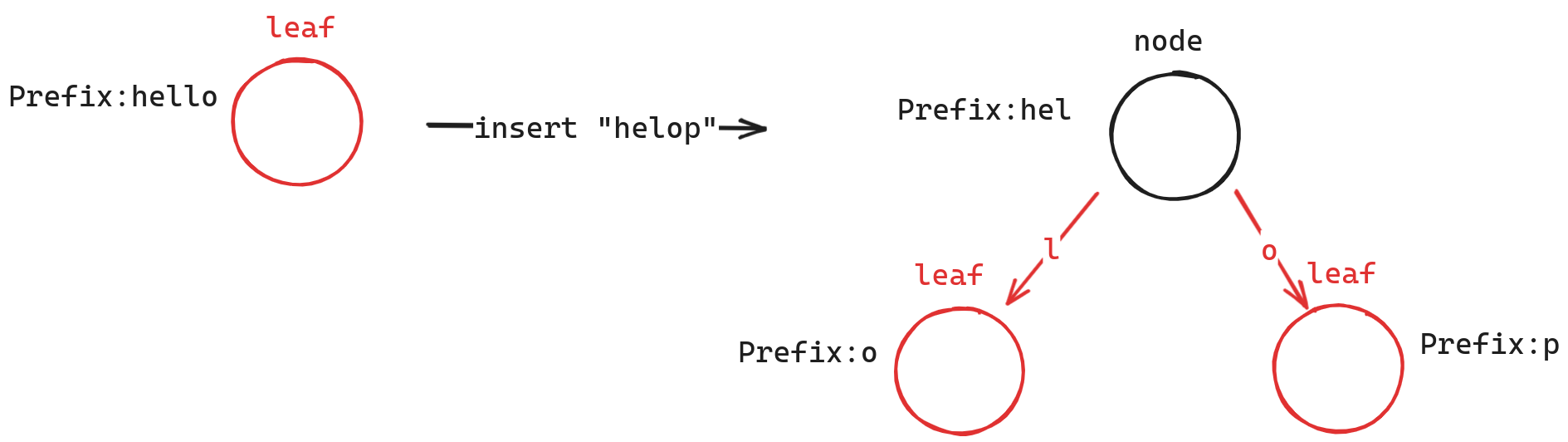
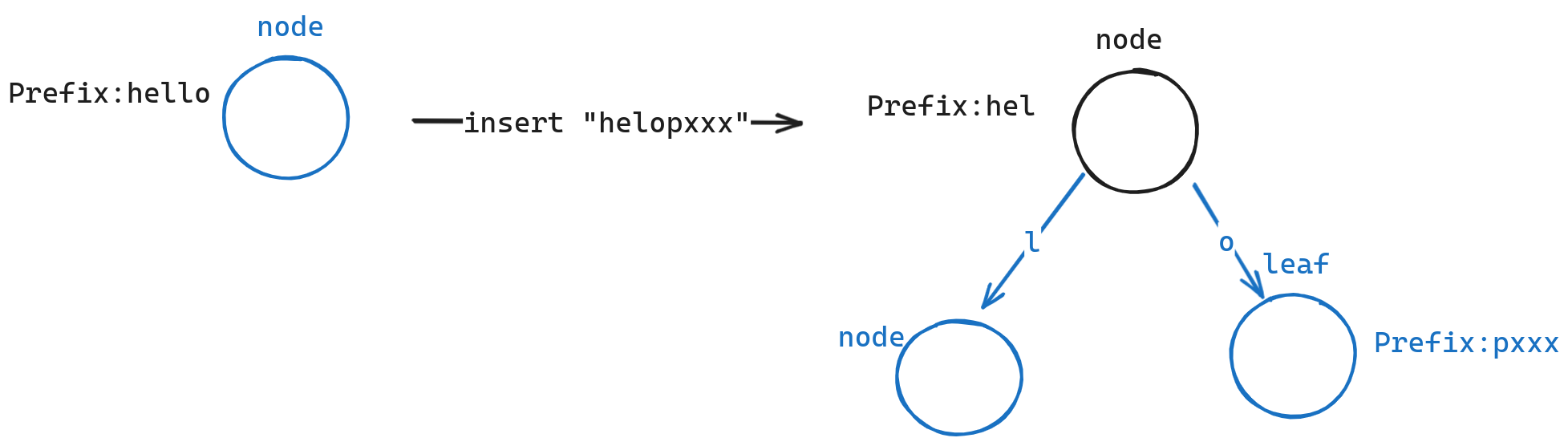
// example: // prefix : hello // key[depth] : heel; // mismatch_position = 2 // replace leaf with Node4 and store both leaves in it auto old_node = node; auto &new_n4 = Node4::New(*this, node);
// new prefix // new_n4's prefix is he new_n4.prefix.Initialize(*this, key, depth, mismatch_position);
// old_node's prefix change to llo auto key_byte = old_node.GetPrefix(*this).Reduce(*this, mismatch_position);
// insert at position Node leaf_node; Leaf::New(*this, leaf_node, key, depth + 1, row_id); Node::InsertChild(*this, node, key[depth], leaf_node); returntrue; }
参数含义:
node 即为当前要进行插入的节点
key 即为要插入的 key
depth:即当前已经处理到 key 的第几个 byte,举个例子,key 为 hello,depth 为 3,那么说明 he 已经保存在了 node 的祖先节点中,我们当前要处理的是 l
row_id 即为 key 对应的 value 值
1 2 3 4 5 6 7
boolART::Insert(Node &node, const ARTKey &key, idx_t depth, constrow_t &row_id){ if (!node.IsSet()) { // node is currently empty, create a leaf here with the key Leaf::New(*this, node, key, depth, row_id); returntrue; } }
// .... skip if (node.DecodeARTNodeType() == NType::LEAF) {
// add a row ID to a leaf, if they have the same key auto &leaf = Leaf::Get(*this, node); auto mismatch_position = leaf.prefix.KeyMismatchPosition(*this, key, depth);
// example: // prefix : hello // key[depth] : heel; // mismatch_position = 2 // replace leaf with Node4 and store both leaves in it auto old_node = node; auto &new_n4 = Node4::New(*this, node);
// new prefix // new_n4's prefix is he new_n4.prefix.Initialize(*this, key, depth, mismatch_position);
// old_node's prefix change to llo auto key_byte = old_node.GetPrefix(*this).Reduce(*this, mismatch_position);