About C++ STL
刷题常见语法
function|auto&& dfs
1️⃣ 关于 [572. 另一棵树的子树 ] 代码中的 auto dfs = [&](auto&& dfs, TreeNode* node) -> pair<int, bool> {} 传递 auto&& dfs 的解释。
1 | // 572. 另一棵树的子树 |
🔥 为什么需要在调用 dfs 传递 dfs 自身:为了能够递归调用 dfs,我们需要在 lambda 的内部将其传递给自己。C++ 的 lambda 本身是不能直接递归的,因为它只是一个匿名函数对象,不知道如何调用自身。因此,我们显式地将 dfs 作为参数传递给它自身,以便在递归时能正确调用。
2️⃣ 如果要简化调用方式(即不重复传入 dfs),那可以这样定义:
1 | auto dfs = [&](this auto&& dfs, TreeNode* node) -> pair<int, bool> { |
3️⃣ 当然也可以使用 function<pair<int, bool>(TreeNode*)>dfs = [&](TreeNode* node) -> pair<int, bool> {}; 这样就只需要传一个参数,但是也显得代码有些臃肿,看个人习惯,我比较习惯直接用 function 而不是 auto,也可以是:auto&& dfs = [&](auto&& dfs, TreeNode* node) -> pair<int, bool> {};
->,. 常见用处
. 是结构体的成员运算符。用于通过对象或引用直接访问对象的成员。
1 | struct MyStruct { |
-> 是指针指向其成员的运算符。组合操作符,相当于先解引用指针,再通过 . 访问成员。
1 | MyStruct* ptr = &obj; |
其它用法:
pair<int, int> p使用p.first
1 | // 对象 |
- 迭代器通常是一个对象(例如容器的迭代器),但它通常表现为类似指针的行为,所以迭代器 iterator 使用
->来解引用访问元素
1 | // 迭代器是对象 |
- 关于 for 在
map与pair中的遍历
1 | unordered_map<int, int> mp{{1, 2}, |
常见数据结构数值大小
size_t:是一种在 C 和 C++ 中常见的无符号整数类型,它用于表示某个对象或类型在内存中的大小,通常由 sizeof 操作符返回。size_t 的定义在标准头文件 <stddef.h>(C 中)或 <cstddef>(C++ 中)中。
- 无符号类型:
size_t是无符号整数,这意味着它不能表示负值(始终 >= 0)。 - 平台相关:
size_t的具体大小依赖于平台的架构。在32位系统上,size_t通常为 4 字节(32 位);在64位系统上,它通常为 8 字节(64 位)。 - 典型用途:
size_t主要用于数组索引、内存大小计算、malloc和calloc等内存分配函数的返回值。
1 | // 像 STL 的容器 size() 函数返回值是 size_t,而 size_t 是一个与机器相关(32bit,64bit)的无符号整数类型, |
其他常见数据结构类型
| 数据类型 | 字节大小 | 数值范围 |
|---|---|---|
| char | 1 | -128 到 127 或 0 到 255(无符号) |
| signed char | 1 | -128 到 127 |
| unsigned char | 1 | 0 到 255 |
| short | 2 | $-2^{15}$ 到 $2^{15}-1$ |
| int | 4 | $-2^{31}$ 到 $2^{31}-1$ |
| long | 4 或 8 | … |
| long long | 8 | $-2^{63}$ 到 $2^{63}-1$ |
| wchar_t | 2 或 4 | … |
| char16_t | 2 | 0 到 $2^{16}-1$ |
| char32_t | 4 | 0 到 $2^{32}-1$ |
| size_t | 4 或 8(根据机器而定) | 0 到 $2^{32}-1$ 或者 0 到 $2^{64}-1$ |
atoi(), stoi(), iota(), itoa() 与 c_str()
c_str():将string转为char*,即把 C++ 字符串对象转换为 C 风格的字符串(以 \0 结尾的字符数组)
1 | // const char* c_str() const noexcept; |
itoa():Integer to ASCII;将整数转换为 C 风格的字符串(即以 \0 结尾的字符数组),返回指向转换后字符串的指针,即参数 str 的地址iota():Incremental Fill;将指定范围内的每个元素赋值为一个递增的值,通常用于生成序列
itoa()为 C 库函数
1 | // char* itoa(int value, char* str, int base); |
atoi():ASCII to Integer;将char*转为int,因此对于一个字符串 str 我们必须调用c_str()的方法把这个string转换成const char*类型;不会做范围检查,如果超出范围的话,超出上界,则输出上界,超出下界,则输出下界。
atoi()为 C 库函数
1 | // int atoi(const char* str); |
stoi():String to Int;将string转为int,且会做范围检查,默认范围是在 int 的范围内的,如果超出范围的话则会 runtime error.stof():String to Float;将string转为float,同上to_string()
1 | // int stoi(const std::string& str, size_t* pos = 0, int base = 10); |
*max_element() 与 *min_element()
std::max_element() 和 std::min_element() 分别是取「最大值」和「最小值」的函数
C++ 20 也可以使用 ranges::max_element() 与 ranges::min_element()
1 | std::vector<int> v{3, 1, -4, 1, 5, 9}; |
__builtin_popcount(nums[i])
__builtin_popcount(nums[i]) 是 GCC 和 Clang 编译器中的内置函数,用于计算一个整数中二进制位为 1 的数量。
1 | // 3011. 判断一个数组是否可以变为有序 |
resize() 知多少
ans.resize(n, avg) 多出的空间用 avg 补全,数组变短则直接截断。
ranges::nth_element()
相关例题:1738. 找出第 K 大的异或坐标值
ranges::nth_element(vec, vec.end() - k) 求取第 k 大的数并放在对应位置,左边比其小,右边比其大,但顺序不保证。
1 | // 1738. 找出第 K 大的异或坐标值 |
lower_bound() 与 upper_bound()
lower_bound() 和 upper_bound() 都是利用「二分查找」方法在排序数组中进行查找。
lower_bound(nums.begin(), nums.end(), num):找第一个大于或等于 num 的数字upperer_bound(nums.begin(), nums.end(), num):找第一个大于 num 的数字
1 | // 2529. 正整数和负整数的最大计数 |
等价于 ranges::equal_range()
1 | class Solution { |
std::move() 与右值表达式
1. 什么是右值和左值?
在 C++ 中,表达式的值可以分为两种类型:左值(lvalue) 和 右值(rvalue)。
左值(lvalue):
左值表示一个具有持久存储(可以取地址)的对象,通常是变量或可以出现在赋值操作符左边的表达式。
例如:变量、数组元素、对象的成员等。
示例:
1
2int x = 10;
x = 20; // x 是一个左值,可以赋值。
右值(rvalue):
右值表示一个临时值或不持久存储的值,通常是表达式的结果,如常量、临时对象、运算结果等。右值通常无法取地址,也不能在赋值操作符的左边使用。
示例:
1
2int y = 10 + 20; // 10 + 20 是一个右值,只是一个计算结果。
int z = 30; // 30 是一个右值。
2. 右值引用(rvalue reference)
右值引用是 C++11 引入的一种新特性,它允许你通过引用操作右值。它的语法是在类型后面加上 &&,例如:int&& 表示一个右值引用。
右值引用的用途:
- 移动语义:允许通过移动(而不是复制)资源来优化性能,特别是对于涉及大量数据的对象(如大数组、字符串等)。
- 完美转发:在模板编程中使用,允许将函数参数完美转发给另一个函数。
右值引用的示例:
1
2int x = 10;
int&& rvalueRef = 10; // 10 是右值,rvalueRef 是一个右值引用。
3. std::move() 的作用
std::move() 是 C++ 标准库中的一个函数模板,用于将一个左值显式地转换为右值引用。这种转换允许开发者以右值引用的方式来处理本应是左值的对象,从而触发移动语义。
**为什么需要
std::move()**:- 移动语义:在实现对象移动时(例如在
std::vector中),你可以通过std::move()将资源从一个对象“移动”到另一个对象,而不是复制它们。这样可以避免不必要的资源分配和释放,极大提高性能。 - 避免复制:通过
std::move(),你可以明确告诉编译器,你不再需要某个对象的值,所以可以将其资源移动到另一个对象中。
- 移动语义:在实现对象移动时(例如在
std::move()的示例:1
2
3
4
5
6
7
8
9
10
11
12
int main() {
std::string str = "Hello, World!";
std::string newStr = std::move(str); // str 的内容被移动到 newStr 中。
std::cout << "str: " << str << std::endl; // str 现在可能为空。
std::cout << "newStr: " << newStr << std::endl; // newStr 拥有 "Hello, World!"。
return 0;
}输出:
1
2str:
newStr: Hello, World!在这个例子中,
std::move(str)将str转换为一个右值引用,这样newStr可以接管str的资源,而不需要复制字符串的内容。str在移动后,其内部资源(如字符串数据)被转移到newStr,因此str变为空或处于未定义状态。
4. 移动语义与对象的生命周期
当对象的资源被移动后,原对象通常会被清空或置于一种安全的“空”状态。你不应再依赖或使用已移动的对象,除非明确知道它处于什么状态。
移动构造函数:
当一个对象被移动时,通常会调用它的移动构造函数。移动构造函数接受一个右值引用,并将资源从旧对象移动到新对象。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13class MyClass {
public:
MyClass() : data(new int[100]) {}
~MyClass() { delete[] data; }
// 移动构造函数
MyClass(MyClass&& other) noexcept : data(other.data) {
other.data = nullptr; // 旧对象的指针设为 nullptr,表示资源已被转移。
}
private:
int* data;
};
5. std::move() 与右值引用的通俗理解
- 右值引用:你可以把右值引用看作是一个能够接管“临时对象”所有权的“特殊指针”,它可以直接操作这些临时对象而不会额外复制数据。
- **
std::move()**:它并不是真正“移动”了什么东西,而是“转换”了一个左值,使其变得可以被视为右值(临时对象),这样你就可以使用右值引用来操作它。其背后是为了优化性能,减少不必要的资源复制。
move 总结
- 右值引用(
int&&)允许你捕获和操作临时对象,从而实现更高效的资源管理。 std::move()是一种显式的类型转换工具,将左值转换为右值引用,告诉编译器可以“安全地”移动这个对象的资源。- 使用
std::move()和右值引用,可以避免不必要的复制操作,优化代码的执行效率,尤其是在处理大量数据的对象时。
C++ ranges 包
该包位于
#include <algorithm>
1 |
|
关于 static auto x = []() 的用法解析
推荐阅读:关于 static auto x = 的用法解析
1 | static const auto _ = []() { |
ios::sync_with_stdio(false)
- 作用: 这行代码用于解除 C++ 标准流(cin, cout, 等)与 C 标准流(scanf, printf, 等)的同步。
- 原因: 在 C++ 中,cin 和 cout 默认与 scanf 和 printf 这类 C 的输入输出流同步,以确保它们可以混合使用而不会出现顺序问题。然而,这种同步会带来性能开销。
- 效果: 将 ios::sync_with_stdio(false) 设为 false 后,cin 和 cout 不再与 C 标准流同步,因此可以提高输入输出的效率,但这也意味着你不应再混用 C 和 C++ 的输入输出函数,否则可能会导致未定义行为。
cin.tie(nullptr)
- 作用: cin.tie(nullptr) 用于解除 cin 和 cout 之间的绑定关系。
- 原因: 默认情况下,cin 和 cout 是绑定在一起的,这意味着在每次使用 cin 进行输入操作前,cout 会自动刷新缓冲区,以确保输入输出顺序的正确性。然而,这种绑定关系在处理大量数据时会带来性能损失。
- 效果: 将 cin 的绑定关系设为 nullptr 后,cout 不会自动刷新缓冲区,从而提高了程序的运行效率。但这意味着你需要手动刷新输出缓冲区(通过 cout.flush() 或 endl 等方式),以确保输出顺序正确。
总结
这两行代码通常用于竞赛编程或需要快速处理大量输入输出的程序中,能够显著提高输入输出的性能。然而,需要注意的是,它们可能会改变输入输出行为的某些细节,因此在启用这些优化时应确保不混用 C 和 C++ 的输入输出函数,并在需要时手动刷新输出缓冲区。
- 使用
#include<bits/stdc++.h>指令,您可以轻松将大多数标准 C++ 头文件包含在代码中(面试中的 ACM 模式经常使用该标准库函数) bits/stdc++.h是 GCC 专用的头文件,在使用 Clang 的 MacOS 上默认不可用。要修复“文件未找到”错误,您可以创建自己的stdc++.h文件并将其放在 Clang 可以找到的目录中。
类型转换 static_cast<int>(val)
C++ 提供了几种不同的类型转换操作符,每种都有特定的用途和使用场景:
- static_cast:基本数据类型之间的转换(如 int 转 float)
- dynamic_cast:用于处理包含多态的类层次结构的类型转换
- const_cast:修改变量的 const 或 volatile 修饰符,允许去除或增加这些修饰符
- reinterpret_cast:最危险的类型转换操作符,主要用于在指针或引用之间进行非常规的、非安全的类型转换
push() 与 emplace()
对于 map 也好,pair 也好,或者是对象,emplace 都能直接构造。
1 | std::map<int, std::string> myMap; |
C/C++ __builtin 超实用位运算库函数
__builtin_ctz() / __builtin_ctzll()
返回括号内数字的二进制表示数末尾 0 的个数
1 |
|
__builtin_clz() / __builtin_clzll()
返回括号内数字的二进制表示数前导 0 的个数
1 |
|
__builtin_popcount()
返回括号内数字的二进制表示数 1 的个数
1 |
|
__builtin_parity()
判断括号中数字的二进制表示数 1 的个数的奇偶数(偶数返回 0,奇数返回 1)
1 |
|
__builtin_ffs()
返回括号中数字的二进制表示数的最后一个 1 在第几位(从后往前算)
1 |
|
STL
容器库是类模板与算法的汇集,允许程序员简单地访问常见数据结构,例如队列、链表和栈。
有三类容器:
- 顺序容器
- 关联容器
- 无序关联容器
容器管理为其元素分配的存储空间,并提供直接或间接地通过迭代器(拥有类似指针属性的对象)访问它们的函数。
C++ 标准模板库(STL)提供了一系列强大的容器,这些容器封装了常见的数据结构,支持各种操作和算法。
一旦 STL 容器中有 find() 方法,那么判断方法一般是 stl.find(val) != stl.end().
⚠️ find 函数只有在「关联容器」和「string」中存在:
- 前者返回迭代器 iterator
- 后者 If no matches were found, the function returns string::npos .

顺序容器
顺序容器实现能按顺序访问的数据结构
array:静态的连续数组vector:动态的连续数组deque:双端队列forward_list:单链表list:双链表
关联容器
关联容器实现能快速查找「 $O(log n)$ 复杂度」的数据结构
set:唯一键的集合,按照键排序map:键值对的集合,按照键排序,键是唯一的multiset:键的集合,按照键排序multimap:键值对的集合,按照键排序
无序关联容器
无序关联容器提供能快速查找「均摊 $O(1)$,最坏情况 $O(n)$ 复杂度」的无序(哈希)数据结构
unordered_set:唯一键的集合,按照键生成散列unordered_map:键值对的集合,按照键生成散列,键是唯一的unordered_multiset:键的集合,按照键生成散列unordered_multimap:键值对的集合,按照键生成散列
容器适配器
容器适配器提供顺序容器的不同接口
stack:适配一个容器以提供栈(LIFO 数据结构)queue:适配一个容器以提供队列(FIFO 数据结构)
迭代器非法化
- 只读方法决不非法化迭代器或引用
- 修改容器内容的方法可能非法化迭代器和/或引用
举个例子:
1 |
|
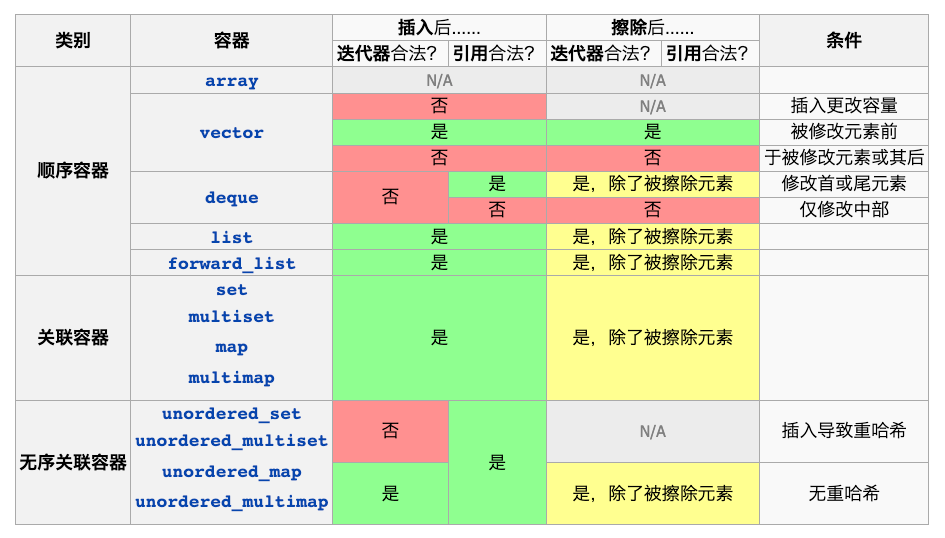
迭代器非法化总结表格:
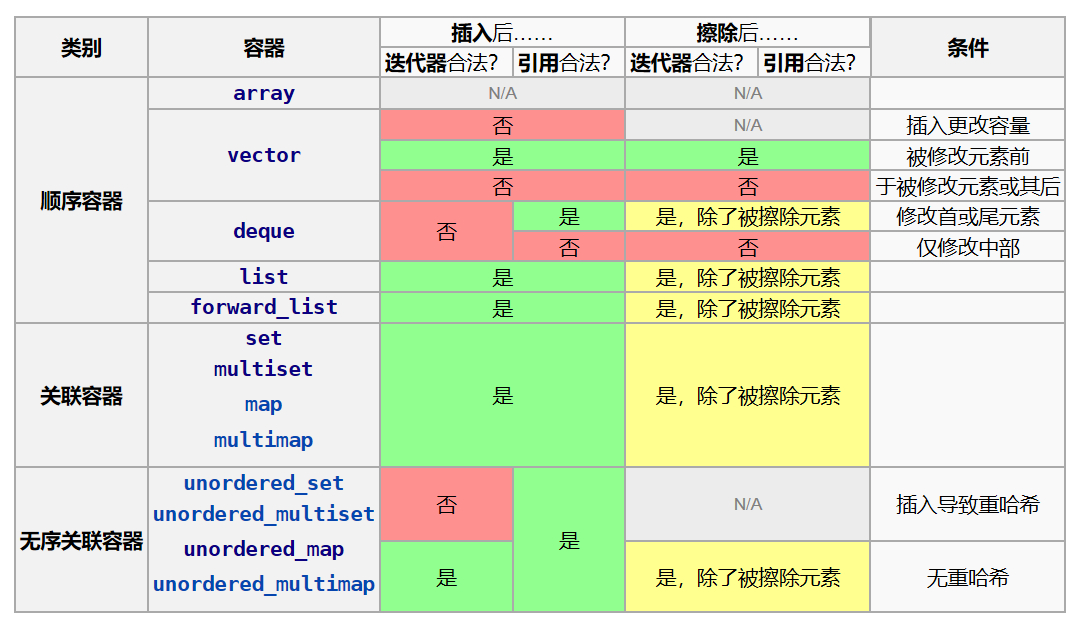
这里的插入指代任何添加一或多个元素到容器的方法:
因为插入过程可能会导致容器扩容(
capacity变化),扩容后会释放原有的空间,而迭代器依然指向原有空间中的位置,此时该迭代器变成野指针,导致无法访问!
insertpush_backpush_frontoperator[]也算,因为也存在插入的可能性
而擦除指代任何从容器移除一或多个元素的方法:
擦除后迭代器失效是因为删除的是最后一个有效元素,然后删除后该迭代器指向容器的非有效位置!

erasepop_backpop_frontclear
尾后迭代器需要特别留意。通常像指向未被擦除元素的正常迭代器一般非法化此迭代器。
故 std::set::end 决不被非法化,std::unordered_set::end 仅在重哈希时被非法化,std::vector::end 始终被非法化(因为它始终出现在被修改元素后),以此类推。
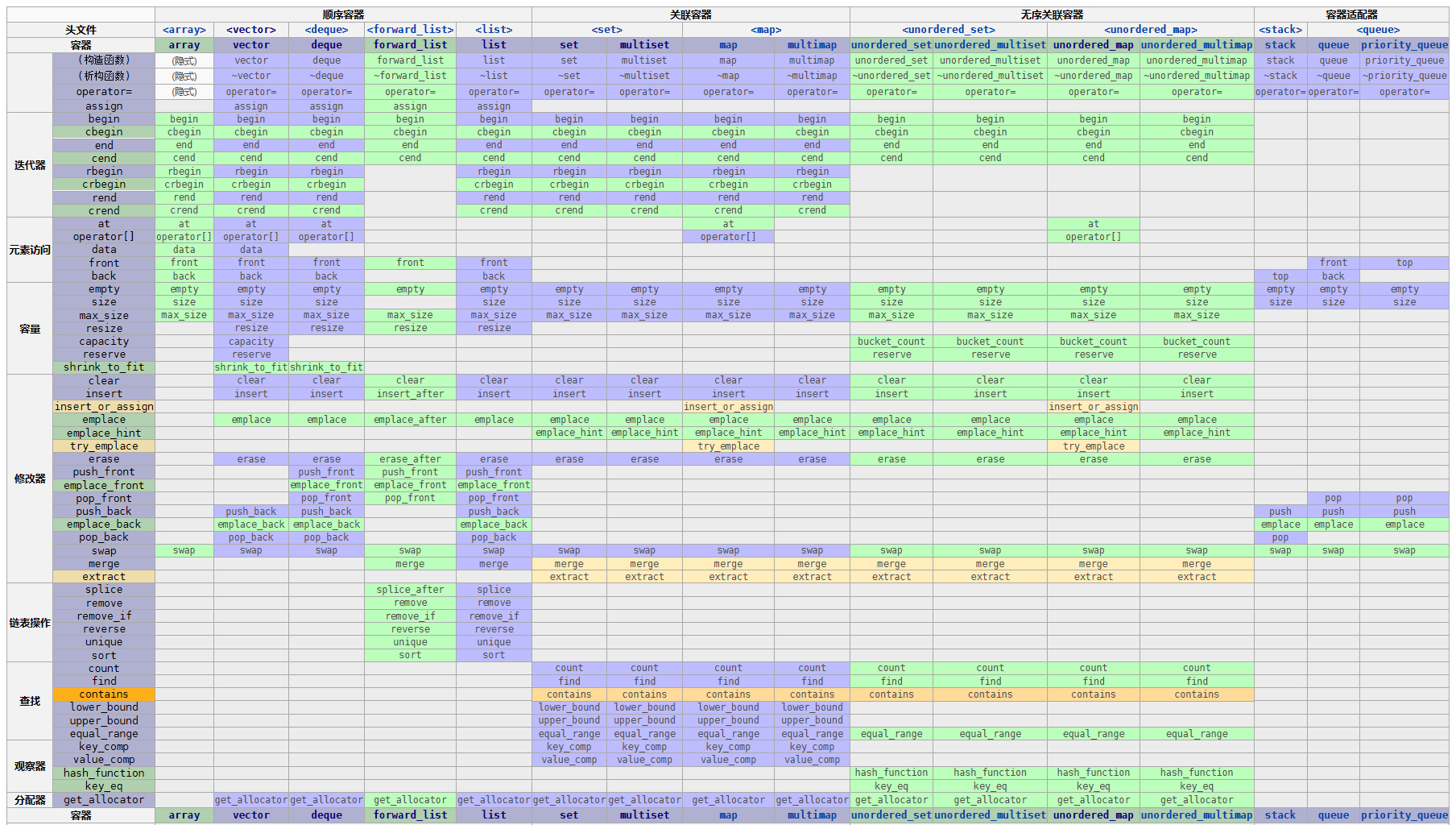
STL 成员函数
成员函数一览表

bitset|位图
std::bitset 也称「位图」,非常常用
1 | template <size_t N> |
bitset 的初始化方式:
1 | std::bitset<N> bitset1; // 创建一个长度为 N 的 bitset,所有位都被初始化为 0 |
方法:
| 方法 | 功能 |
|---|---|
| b.any() | b 中是否存在置为 1 的二进制位? |
| b.none() | b 中不存在置为 1 的二进制位? |
| b.count() | b 中置为 1 的二进制位的个数 |
| b.size() | b 中二进制位的个数 |
| b[pos] | 访问 b 中在 pos 处的二进制位 |
| b.test(pos) | b 中在 pos 处的二进制是否为 1? |
| b.set() | 把 b 中所有二进制位都置为 1 |
| b.set(pos) | 把 b 中在 pos 处的二进制位置为 1 |
| b.reset() | 把 b 中所有二进制位都置为 0 |
| b.reset(pos) | 把 b 中在 pos 处的二进制位置为 0 |
| b.flip() | 把 b 中所有二进制位取反 |
| b.flip(pos) | 把 b 中在 pos 处的二进制位取反 |
| b.to_ulong() | 用 b 中同样的二进制位返回一个 unsigned long 值 |
| os << b | 把 b 中的位集输出到 os 流 |
1 | std::bitset<4> b1("1100"); |
这些函数使得 std::bitset 成为处理位级别数据的强大工具。
std::bitset 还支持「位操作符」、「位移操作符」和「比较操作符」:
1 | std::bitset<4> b1("1100"); |
1 | std::bitset<4> b1("1100"); |
1 | std::bitset<4> b1("1100"); |
string
str[i] 取到的是 char 字符
c_str():const CharT* c_str() const;
string 可以利用以下几个方法模拟 stack
push_back()pop_back()
erase()
append()
length()
find():finds the first occurrence of the given substring
1 |
|
rfind():find the last occurrence of a substring
string::npos:一般和find()搭配使用
1 | // string search functions return npos if nothing is found |
查找,包括前面
find与rfind
find_first_of():size_type find_first_of( const basic_string& str, size_type pos = 0 ) const;
find_first_not_of()
find_last_of()
find_last_not_of()
operations
starts_with() [C++ 20]
ends_with() [C++ 20]
contains() [C++ 23]
substr(size_type position = 0, size_type count = npos):获取子串
int/float 转为 string
to_stringto_wstring
string 转为数值
stoi()stof()stod()stol()stoll()
array
array 是一个固定大小的数组封装容器。
1 | std::array<int, 5> arr = {1, 2, 3, 4, 5}; |
vector
动态数组,支持随机访问,内存是连续的。
常用方法:
push_back(value):在末尾添加元素。pop_back():删除末尾元素。insert(vec.begin(), value):在指定位置插入元素。erase(vec.begin()):删除指定位置的元素。clear():清空容器。resize(n):调整容器大小。at(index):访问指定位置的元素。front():访问第一个元素。back():访问最后一个元素。empty():检查容器是否为空。size():返回容器中元素的数量。capacity():返回容器的容量。reserve(n):预留至少 n 个元素的空间。
deque
双端队列,支持在两端快速插入和删除。内存可能不连续,支持常数时间的随机访问。
push_back(value)push_front(value)pop_back()pop_front()front()back()erase(position)insert(position, value)at(index)empty()size()
set [有序]
集合,存储唯一元素,元素按顺序排列,底层通常是红黑树。
插入、删除、查找的时间复杂度为 $O(log n)$。
insert(value)emplace(value)erase(position)erase(value)find(value)count(value)empty()size()contains(value)[C++ 20]
multiset [有序]
允许存储重复元素的集合,元素按顺序排列,底层通常是红黑树。
插入、删除、查找的时间复杂度为 $O(log n)$。
滑动窗口 +
multiset
1 | // 1438. 绝对差不超过限制的最长连续子数组 |
insert(value):插入元素。erase(position):删除指定位置的元素。erase(value):删除与指定值相等的元素。find(value):查找指定值的元素。count(value):统计与指定值相等的元素数量。clear():清空容器。empty():检查容器是否为空。size():返回容器中元素的数量。
map [有序]
键值对集合,按键排序,键唯一,底层通常是红黑树。
插入、删除、查找的时间复杂度为 $O(log n)$。
insert({key, value}):插入键值对。erase(position):删除指定位置的键值对。erase(key):删除指定键的键值对。find(key):查找指定键的键值对。count(key):统计指定键的键值对数量(返回 0 或 1)。clear():清空容器。empty():检查容器是否为空。size():返回容器中元素的数量。at(key):访问指定键的值(若键不存在则抛出异常)。operator[](key):访问或插入指定键的值。
multimap [有序]
允许重复键的键值对集合,按键排序,底层通常是红黑树。
插入、删除、查找的时间复杂度为 $O(log n)$。
insert({key, value}):插入键值对。erase(position):删除指定位置的键值对。erase(key):删除指定键的键值对。find(key):查找指定键的键值对。count(key):统计指定键的键值对数量。clear():清空容器。empty():检查容器是否为空。size():返回容器中元素的数量。
unordered_map
无序容器使用哈希表实现,元素无序排列,插入和查找操作平均时间复杂度为 O(1)。
键值对集合,键唯一,元素无序排列,底层为哈希表。
插入、删除、查找的平均时间复杂度为 $O(1)$。
unordered_set
集合,存储唯一元素,元素无序排列,底层为哈希表。
插入、删除、查找的平均时间复杂度为 $O(1)$。
unordered_multimap
键值对集合,键唯一,元素无序排列,底层为哈希表。
插入、删除、查找的平均时间复杂度为 $O(1)$。
unordered_multiset
允许存储重复元素的集合,元素无序排列,底层为哈希表。
插入、删除、查找的平均时间复杂度为 $O(1)$。
std::pair<int, int>
将两个值组合在一起,常用于关联容器(如 std::map)
p.first:第一个元素p.second:第二个元素make_pair(val_1, val_2):创建一个pair对象
stack
后进先出(LIFO)的栈,默认使用 std::deque 作为底层容器。
push(value)pop()top()empty()size()
queue
先进先出(FIFO)的队列,默认使用 std::deque 作为底层容器。
queue为单端队列,deque为双端队列
push(value)pop()front()back()empty()size()
priority_queue
top访问队头元素empty队列是否为空size返回队列内元素个数push/emplace插入元素到队尾(后者为 in-place insert)pop弹出队头元素swap交换内容
1 | const auto data = {1, 8, 5, 6, 3, 4, 0, 9, 7, 2}; |
关于 swap 函数:
1 | int main() |
Output:
1 | s1 [4]: 4 3 2 1 |
iterator
begin() 与 end():返回指向数组开头和末尾之后一个位置的迭代器
cbegin() 与 cend():返回指向数组开头和末尾之后一个位置的常量迭代器
rbegin() 与 rend():返回指向数组末尾和开头之前一个位置的反向迭代器
crbegin() 与 crend():返回指向数组末尾和开头之前一个位置的常量反向迭代器
常量迭代器只读,不可以修改对应的元素值。
本文由 Yikun Wu 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处




