
陆续一个月了,腾讯、阿里云、淘天、高德、拼多多、字节、美团… 能投的都投了。
建议:多刷面经,可以快速积累场景题、设计题、多线程题,而且能快速 get 到高频八股,比如 oom、cpu 使用率高、慢查询治理…
找暑期哪有不疯的,运气也是非常重要。
最后祝各位早日 oc(也祝我能 oc),无需过度焦虑,才四月初,正是发力期,过段时间一堆鸽穿的。
腾讯 CDG 金融科技|后台开发
一面
算法题
2. 两数相加 (从头开始加)|ACM 模式
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:

1 | 输入:l1 = [2,4,3], l2 = [5,6,4] |
1️⃣ 迭代:先按照链表访问顺序逐个累加(类似大数之和),有进位就加到下一个节点。
1 | /** |
另一种调用输入输出方式:
1 | // 输入: |
如果输入末尾有空格:
1 | ␣ 表示空格 |
1 | // 方法一 |
2️⃣ 递归:直接在 L1 链表上改(L2 比 L1 长则交换 swap 节点),看似递归,实则迭代,本质递归的只有头节点。

1 |
|
思考:本题的链表是从数字的最低位开始的,如果改成从最高位开始,要怎么做呢?
445. 两数相加 II (从尾开始加)
给你两个 非空 链表来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
你可以假设除了数字 0 之外,这两个数字都不会以零开头。
示例1:

1 | 输入:l1 = [7,2,4,3], l2 = [5,6,4] |
1️⃣ 迭代:本题等价于「206. 反转链表(迭代写法)」+「2. 两数相加(迭代写法)」
1 | /** |
2️⃣ 递归:本题等价于「206. 反转链表(递归写法)」+「2. 两数相加(递归写法)」
1 | /** |
3️⃣ 栈:对两个链表分别入栈 s1 和 s2
1 | /** |
72. 编辑距离 |ACM 模式
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
1 | 输入:word1 = "horse", word2 = "ros" |
1️⃣ 递推 · 动态规划|ACM 模式代码:我初始化的时候只初始化 dp[0][0] = 0 😭
1 |
|
自我介绍|面试官
我们这边主要做信用卡分期和信用卡还款这一块的业务(微信信用卡还款、分期之类的业务),聚焦金融,所以对事务性开发比较重视。
介绍面试流程:
- 让你做自我介绍,然后简单聊一聊
- 两题笔试题 40 分钟,做完针对笔试聊一聊
- 针对简历内容和基础知识面谈
笔试题
八股文
如何高效地将字符串/
char[]进行追加,假设char[]开辟了很大的空间:memcpy处理底层会比较快
1. C++ 虚函数实现机制
C++ 虚函数用于实现多态,它的核心机制依赖于虚函数表 vtable 和虚指针 vptr,当一个类中包含虚函数时:
- 编译器会为该类生成一个虚函数表,其中存储了该类所有虚函数的指针
- 每个对象都会包含一个虚指针,它指向该类的虚函数表
- 通过虚指针 + 虚函数表,可以在运行时调用正确的函数,实现动态绑定
没有虚函数的普通继承|静态绑定,编译时绑定
- 由于
show()不是虚函数,调用obj->show()在编译时已决定 调用Base::show(),不会检查Derived是否有show()。
1 |
|
使用虚函数|动态绑定,运行时绑定
show()是 虚函数(virtual),因此Base* obj在运行时会调用 Derived::show()。- 这个过程是 通过虚指针(vptr) 和 虚函数表(vtable)实现的。
1 |
|
举个例子:代码结构如下
1 | class Base { |
虚函数表的内存分布:
1 | Base 对象: |
虚函数表 vtable:
1 | Base vtable: |
如果是多继承下的虚函数,当一个类继承多个基类时,每个基类都有自己的 vptr
1 |
|
由于 Derived 继承了 A 和 B,其内存布局如下:
1 | Derived 对象: |
2. 虚函数外的成员函数会放在虚函数表中吗?还是其他什么地方?
在 C++ 中,虚函数以外的普通成员函数 并不存储在对象的内存中,而是存储在代码段(text segment)。这是因为:
- 成员函数是代码,而不是数据,成员变量(数据成员)存储在对象本身的内存中,而成员函数属于程序代码,并不会在每个对象中占据额外空间。
- 所有对象共享同一份成员函数:由于非虚函数的调用是静态绑定的(编译时确定),同一类的所有对象都共用相同的成员函数。
- 函数地址不会存储在对象中:调用普通成员函数时,编译器直接用 函数地址 进行调用,不需要在对象中存储额外的信息。
普通成员函数和静态成员函数都是存储在「代码区」,虚函数本身存储在「代码区」,但如果有虚函数,每个对象会包含一个虚表指针 vptr 用于指向虚函数表 vtable,而虚函数表通常存储在「静态存储区」。
3. 一个派生类继承两个父类,这两个父类同时有一个共同基类,如果你去调用两个父类的基类对象函数,会有问题吗?
注:在 Java 中,由于 Java 不支持多重继承,所以菱形继承问题也不存在。 Java 使用接口来替代多重继承,接口只定义了一些抽象的方法,而没有具体的实现。
这是 C++ 多重继承造成的菱形继承问题,如果一个派生类继承了两个拥有相同基类的父类,那么基类的成员会被继承两次,这会导致 “二义性问题” 和 “冗余存储”。
❌ 编译错误!
1 |
|
4. 出现二义性问题,在 C++ 中怎么解决这种菱形继承问题?==> 虚基类 Base|class Derived : virtual public Base
1️⃣ 解决方案一:使用作用域解析符
缺点:Derived 仍然包含 两个 Base 实例,数据冗余,而且每次调用 show() 需要手动指定作用域,不优雅。
1 | int main() { |
2️⃣ 使用虚继承|最佳方案 ✅
虚继承是为了让某个类做出声明,承诺愿意共享它的基类,这个被共享的基类就是虚基类
多继承除了造成命名冲突,还有数据冗余等问题,为了解决这些问题,C++ 引进了「虚继承」
这样能够保证 Derived 只含有一个唯一的 Base 实例。
1 |
|
不使用 virtual 时
Derived会有两个Base对象,导致二义性问题。- 内存浪费(两个
Base子对象的冗余)。
使用 virtual 继承
Parent1和Parent2不会各自包含Base的副本,而是共享同一个Base实例。Derived只会有一个Base实例,所以调用show()时不会有二义性。
再看个虚继承的例子:
1 |
|
将 Base0 类作为它的直接派生类 Base1 和 Base2 的虚基类,即 Base1 虚继承 Base0,Base2 虚继承 Base0。之后 Derived 再继承 Base1 和 Base2,在 Derived 对象里面就不会存在 Base0 类的双份的成员。
Derived 对象包含着从 Base1 继承的成员和从 Base2 继承的成员,但是从 Base1 继承的 Base0 成员实际上这个地方放了一个指针,这个指针指向真正的 Base0 成员,Base2 的也是。所以实质上从最远的基类继承过来的成员,在最远派生类中只有一份。

5. STL 库中 vector、list、map 实现的底层原理和应用场景?
关于 STL 库中所有的结构的底层实现原理:https://zhuanlan.zhihu.com/p/542115773
顺带了解了 set、map、unordered_map、unordered_set 之间区别:
set、map:底层使用红黑树实现,有序,插入、查找、删除的时间复杂度为 $O(logn)$
- 优点:有序性,内部实现红黑树使得很多操作都在 $O(logn)$ 时间复杂度下完成
- 缺点:空间占用率高,需要额外保存父节点、孩子节点和红/黑性质
unordered_set、unordered_map:底层使用哈希表实现,无序,查找的时间复杂度为 $O(1)$
- 优点:因为内部实现了哈希表,因此其查找速度非常的快
- 缺点:哈希表的建立比较费时
1️⃣ vector 动态数组
vector底层是动态数组,元素连续存储在堆上- 自动扩容机制:
- vector 采用几何增长策略(通常是 2 倍扩容)
- 当
size() == capacity()时,会申请更大的内存空间,然后拷贝旧数据到新空间 - 由于 realloc 可能导致数据搬移,
push_back()的均摊时间复杂度为 $O(1)$,但最坏情况 $O(n)$(扩容时)
- ❓所以有可能 vector 的插入操作可能导致迭代器失效:因为 vector 动态增加大小时,并不是在原空间后增加新空间,而是以原大小两倍在开辟另外一片较大空间,然后将内容拷贝过来,并释放原有空间,所以迭代器失效。
适用场景:
✅ 高效的随机访问(O(1))。
✅ 批量尾部插入/删除(push_back())。
❌ 不适合频繁插入/删除中间元素(O(n))。
❌ 扩容会导致数据搬移(不适合超大数据集)。
2️⃣ list 双向链表
list底层是双向链表,每个节点存储数据和两个指针- 插入和删除操作非常高效,不影响其他元素
- 不支持随机访问,必须顺序遍历才能找到某个元素 $O(n)$
- 不会发生扩容问题,适合频繁插入/删除的场景
适用场景:
✅ 高效插入/删除(O(1),特别是中间位置)。
✅ 不关心随机访问,仅需遍历。
❌ 不适合频繁随机访问(O(n))。
❌ 额外的指针开销(内存占用比 vector 高)。
3️⃣ map 平衡二叉搜索树——红黑树
map底层实现是红黑树(Red-Black Tree),一种自平衡二叉搜索树- key 是有序的
- 插入、删除、查找 $O(logn)$,因为树的高度是 $O(logn)$
- 迭代遍历按照 key 顺序进行
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
插入 insert() |
$O(log n)$ | 需要维护红黑树平衡 |
删除 erase() |
$O(log n)$ | 删除节点后可能需要旋转 |
查找 find() |
$O(log n)$ | 通过 BST 进行搜索 |
适用场景:
✅ 需要有序存储的数据结构(默认按照 key 递增)。
✅ 需要高效查找、插入、删除(O(log n))。
❌ 不适合频繁变更 key(因为 key 作为 BST 节点的一部分)。
❌ 遍历效率比 unordered_map 低(有序存储开销大)。
6. 红黑树有了解吗?红黑树的查找、插入、删除的时间复杂度?
红黑树是一种自平衡二叉搜索树(BST),广泛应用于 C++ STL 的 map、set、multimap、multiset 以及 Linux 进程调度、内核数据结构等场景。
红黑树在每个节点上存储一个额外的颜色位(红/黑),并满足以下五条性质:
- 每个节点是红色或黑色。
- 根节点必须是黑色。
- 所有叶子节点(NIL)是黑色(有些实现省略 NIL)。
- 红色节点不能连续出现(红色节点的子节点必须是黑色)。
- 任意节点到其所有叶子节点的路径上,黑色节点的数量相同。
这些性质确保了红黑树的近似平衡特性,使得最长路径不超过最短路径的 2 倍。
红黑树的插入、删除、查找的时间复杂度都在 $O(logn)$
红黑树的应用:
C++ STL
map和setLinux 内核任务调度(完全公平调度 CFS):采用红黑树作为调度队列的数据结构,用于管理所有可运行的进程,并确保进程公平分配 CPU 时间
- 每个可运行进程存储在红黑树中,按照
vruntime(虚拟运行时间)排序。vruntime是进程实际运行时间的加权值,nice值(进程优先级)影响vruntime的增长速度。
- 调度器总是选择
vruntime最小的进程运行(即红黑树的最左节点)。 - 进程执行后,
vruntime增长,然后被重新插入红黑树中,确保所有进程轮流执行。
- 每个可运行进程存储在红黑树中,按照
文件系统(Ext3 / Ext4)
Ext3 是 Ext2 的升级版,支持日志,增强数据一致性。
数据结构:
基于 inode 和目录索引(采用
h-tree,即 B+ 树变种)。日志模式:数据日志模式、元数据日志模式、无日志模式。
缺点:大文件性能不佳,目录性能有限。
Ext4 是 Linux 默认文件系统,在 Ext3 基础上做了多项优化:
延迟分配:优化写入性能。
多块分配:减少磁盘碎片。
HTree 索引目录:加速大目录的查找,采用红黑树进行元数据管理。
日志优化:降低磁盘 IO,提高数据一致性。
Redis 有序集合(ZSet)
- ZSet(Sorted Set) 是 Redis 中的一种数据结构,支持有序存储,每个元素带有一个 score 值(排序依据)
- ZSet 的底层数据结构:
- 跳表(Skip List):默认用于有序集合,支持
O(log n)级别的插入、删除、查找。 - 哈希表(Hash Table):用于快速定位元素(score → key)。
- 红黑树(可能被用作持久化存储结构)。
- 跳表(Skip List):默认用于有序集合,支持
7. MySQL 的聚集索引和非聚集索引的区别?
好文:https://blog.csdn.net/white_ice/article/details/115478367
二叉查找树 —— 平衡二叉树 —— B 树
因为内存的易失性。一般情况下,我们都会选择将 user 表中的数据和索引存储在磁盘这种外围设备中。但是和内存相比,从磁盘中读取数据的速度会慢上百倍千倍甚至万倍,所以,我们应当尽量减少从磁盘中读取数据的次数。另外,从磁盘中读取数据时,都是按照磁盘块来读取的,并不是一条一条的读。如果我们能把尽量多的数据放进磁盘块中,那一次磁盘读取操作就会读取更多数据,那我们查找数据的时间也会大幅度降低。如果我们用树这种数据结构作为索引的数据结构,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块。我们都知道平衡二叉树可是每个节点只存储一个键值和数据的。那说明什么?说明每个磁盘块仅仅存储一个键值和数据!那如果我们要存储海量的数据呢?
可以想象到二叉树的节点将会非常多,高度也会极其高,我们查找数据时也会进行很多次磁盘 IO,我们查找数据的效率将会极低!
B 树
图中的 p 节点为指向子节点的指针,二叉查找树和平衡二叉树其实也有,因为图的美观性,被省略了。
图中的每个节点称为页,页就是我们上面说的磁盘块,在 MySQL 中数据读取的基本单位都是页,所以我们这里叫做页更符合 MySQL 中索引的底层数据结构。
从下图可以看出,B 树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,下图中的 B 树为 3 阶 B 树,高度也会很低。基于这个特性,B 树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多。
B+ 树
B+ 树是对 B 树的进一步优化。让我们先来看下 B+ 树的结构图:
根据下图我们来看下 B+ 树和 B 树有什么不同:
1️⃣ B+ 树非叶子节点上是不存储数据的,仅存储键值,而 B 树节点中不仅存储键值,也会存储数据。
之所以这么做是因为在数据库中页的大小是固定的,InnoDB 中页的默认大小是 16KB。
如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的 I/O 次数又会再次减少,数据查询的效率也会更快。
另外,B+ 树的阶数是等于键值的数量的,如果我们的 B+ 树一个节点可以存储 1000 个键值,那么 3 层 B+ 树可以存储 1000×1000×1000=10 亿个数据。一般根节点是常驻内存的,所以一般我们查找 10 亿数据,只需要 2 次磁盘 IO。
2️⃣ 因为 B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。
那么 B+ 树使得范围查找、排序查找、分组查找以及去重查找变得异常简单。而 B 树因为数据分散在各个节点,要实现这一点是很不容易的。
有心的读者可能还发现下图 B+ 树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。
其实上面的 B 树我们也可以对各个节点加上链表。这些不是它们之前的区别,是因为在 MySQL 的 InnoDB 存储引擎中,索引就是这样存储的。
也就是说下图中的 B+ 树索引就是 InnoDB 中 B+ 树索引真正的实现方式,准确的说应该是聚集索引(聚集索引和非聚集索引下面会讲到)。
通过下图可以看到,在 InnoDB 中,我们通过数据页之间通过双向链表连接以及叶子节点中数据之间通过单向链表连接的方式可以找到表中所有的数据。
MyISAM(MySQL 另一存储引擎)中的 B+ 树索引实现与 InnoDB 中的略有不同。在 MyISAM 中,B+ 树索引的叶子节点并不存储数据,而是存储数据的文件地址。


在 MySQL InnoDB 存储引擎中,索引分为聚集索引(Clustered Index) 和 非聚集索引(Secondary Index),二者的区别主要在于数据存储方式和查询性能。
- 聚集索引表示表中存储的数据按照索引的顺序存储,检索效率比非聚集索引高,但对数据更新影响较大;非聚集索引表示数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置。非聚集索引检索效率比聚集索引低,但对数据更新影响较小。
- 聚集索引一个表只能有一个;而非聚集索引一个表可以存在多个。聚集索引存储记录是物理上连续存在;而非聚集索引是逻辑上的连续,物理存储并不连续。
1️⃣ 什么是聚集索引(Clustered Index)?
- 聚集索引 = 数据与索引存储在一起
- B+ 树索引的叶子节点存储了整行数据
- 每张表只能有一个聚集索引(因为数据只能有一种物理存储顺序)
- 主键(PRIMARY KEY)默认是聚集索引,如果没有定义主键,InnoDB 会自动选取一个
UNIQUE索引或创建一个隐式主键
示例
1 | CREATE TABLE users ( |
id是聚集索引,B+ 树的叶子节点存储整个行数据
存储结构
1 | 聚集索引 B+ 树(按 id 组织) |
- 叶子节点存储完整行数据
- 查询
id=2时,B+ 树直接找到整行数据,速度快
特点:
✅ 查询主键时效率高(索引 + 数据一起存储,减少磁盘 I/O)
✅ 范围查询快(数据按主键顺序存储,连续读取)
❌ 插入时如果 id 不是自增,会导致频繁调整 B+ 树,影响性能
❌ 更新主键会导致数据移动,影响性能
2️⃣ 什么是非聚集索引(Secondary Index)?
- 非聚集索引(非主键索引)= 索引和数据分开存储
- B+ 树的叶子节点存储的是主键,而不是数据本身
- 查询时,需要先查索引,再回表查询数据(回表查询,Extra: Using index)
- 比如查询
name='Bob'时,需要先找到id=2,再去主键索引查整行数据
- 比如查询
- 一张表可以有多个非聚集索引
示例
1 | CREATE TABLE users ( |
name是非聚集索引,叶子节点存储的是id而不是整行数据。
存储结构
1 | 非聚集索引 B+ 树(按 name 组织) |
- 叶子节点存储的是
id(主键) - 查询
name='Bob'时,需要先找到id=2,再去主键索引查整行数据
特点
✅ 可以加速非主键字段的查询(如 name)。
✅ 一个表可以有多个非聚集索引(name、age 等)。
❌ 查询时可能需要“回表”查询完整数据,性能较低。
❌ 更新索引字段时,需要维护额外的索引,影响写性能。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
索引虽然能够提高查询性能,但也需要注意以下几点:
- 索引需要占用额外的存储空间。
- 对表进行插入、更新和删除操作时,索引需要维护,可能会影响性能。
- 过多或不合理的索引可能会导致性能下降,因此需要谨慎选择和规划索引。
3️⃣ 聚集索引 vs. 非聚集索引 对比
| 对比项 | 聚集索引(Clustered Index) | 非聚集索引(Secondary Index) |
|---|---|---|
| 存储结构 | 索引叶子节点存储整行数据 | 索引叶子节点存储主键 |
| 查询性能 | 主键查询快(不需要回表) | 需要回表查询完整数据 |
| 索引大小 | 整个表的大小 | 比聚集索引小(只存索引 + 主键) |
| 插入性能 | 主键顺序插入快(如自增 ID) | 插入影响较小 |
| 更新性能 | 更新主键影响大(数据移动) | 更新索引字段影响较大 |
| 排序性能 | 按照主键存储,查询范围快 | 查询非主键字段排序时,可能用索引覆盖 |
| 适用场景 | 主键查询、范围查询、高效分页 | 辅助查询,如 WHERE name='Bob' |
5️⃣ 什么时候选择聚集索引 & 非聚集索引?
✅ 适合用聚集索引(PRIMARY KEY)
- 查询主键:
SELECT * FROM users WHERE id = 10; - 范围查询:
SELECT * FROM users WHERE id BETWEEN 1 AND 100; - 分页查询(ORDER BY 主键):
ORDER BY id LIMIT 10; - 高效数据存储(自增主键 INSERT 快)
✅ 适合用非聚集索引(Secondary Index)
- 非主键查询:
SELECT * FROM users WHERE name = 'Alice'; - 模糊匹配(LIKE):
SELECT * FROM users WHERE name LIKE 'A%'; - 组合索引:
INDEX (name, age)可优化WHERE name='Alice' AND age=25
❌ 避免使用非聚集索引的场景
- 频繁更新索引列(影响性能)
- 非主键大范围查询,可能导致大量回表
8. 谈谈你对 redis 的了解?
Redis 面试题:https://zhuanlan.zhihu.com/p/427496556
范围太广了。
Redis(Remote Dictionary Server) 是一个高性能的 Key-Value 存储 NoSQL 数据库之一,用于缓存、持久化、分布式锁、消息队列等场景。基于内存存储(In-Memory),访问速度远快于磁盘数据库。单线程模型(IO 多路复用),并发性能极高。
支持多种数据结构(String, Hash, List, Set, Sorted Set, HyperLogLog, Bitmap, GeoSpatial)。
数据类型;说明;应用场景
- String:最基础数据类型;缓存字符串、计数器、分布式锁
- List:双向链表;消息队列、文章列表
- Set:无序集合、去重;标签、用户好友关系、抽奖系统
- Hash:存储对象、节省内存;用户信息存储
- Sorted Set (ZSet):有序集合、可排序;排行榜、延时任务队列
Redis 与 Memcached 的区别
| 特性 | Redis | Memcached |
|---|---|---|
| 数据结构 | 多种(String、List、Set、Hash、ZSet) | 仅支持 Key-Value |
| 持久化 | RDB、AOF | 无持久化 |
| 分布式 | 支持主从复制、哨兵、集群 | 需要额外支持 |
| 线程模型 | 单线程(IO 多路复用) | 多线程 |
| 过期策略 | 可配置(LRU、LFU) | FIFO/LRU |
Redis 持久化策略:
- RDB (Redis Database Snapshot)
- 快照存储,定期将数据存储到磁盘
- 触发方式:
save:同步保存,影响性能bgsave:后台异步保存
- 优点:适合灾难恢复(冷启动);备份文件体积小,加载快
- 缺点:可能丢失最近的写入数据(触发快照前的写入)
- AOF (Append-Only File)
- 记录所有写操作,类似 MySQL binlog
- 写模式:
- always:每次写入后 fsync,最安全但慢
- everysec:每秒 fsync,默认
- no:由 OS 决定
- 优点:最高的数据安全性,可用于数据恢复
- 缺点:日志体积大,写入速度较慢
- ✅ 最佳实践:
- 两者结合使用(AOF 提高数据安全性,RDB 提高启动速度)。
appendonly yes+save 900 1(开启 AOF + RDB 定期备份)。
Redis 过期策略:
- 定期删除:Redis 每秒扫描一部分 key,删除已过期的 key(减少开销)。
- 惰性删除:访问 key 时,若已过期则删除。
Redis 淘汰策略:
noeviction:不删除,返回错误
volatile-lru:LRU 淘汰(仅对有 TTL 的 key)
allkeys-lru:淘汰最近最少使用(LRU)key
volatile-random:随机删除 TTL 设定的 key
allkeys-random:随机删除任意 key
volatile-ttl:删除最近过期的 key
Redis 主从复制 & 哨兵 & 集群:
- 主从复制(Master-Slave)
slaveof <master-ip> <port>配置从节点- 主从同步
- 全量复制(初次同步)
- 增量复制(接收后续写操作)
- 读写分离,提高性能;备份数据,防止单点故障
- 哨兵(Sentinel)
- 作用:负责自动故障转移
- 监控 Master 节点的健康状态
- 主节点宕机后,自动提升 Slave 为 Master
- 高可用 Redis 方案
- 作用:负责自动故障转移
- 集群(Cluster)
- Redis Cluster 实现数据分片
- 数据存储在多个节点
- 客户端直连节点(无中心节点)
- 适用于大规模分布式场景(高并发、高数据量)
- Redis Cluster 实现数据分片
Redis 并发控制 & 事务:
- 事务
- MULTI / EXEC / DISCARD 事务机制
- 不支持回滚(失败不会撤销之前的命令)
- Redis 分布式锁
- 使用
SETNX(SET if Not Exists) - 避免并发超卖、分布式任务调度
- 使用
Redis 面试高频问题总结:
- Redis 为什么快:基于内存 + 单线程 IO 多路复用
- 持久化方式:RDB(快照)+ AOF(日志)
- 淘汰策略:LRU、LFU、TTL
- 集群模式:主从复制、哨兵、集群
- 如何防止缓存穿透:布隆过滤器、NULL 缓存
- 如何防止缓存雪崩:设置不同 TTL、分布式缓存
缓存穿透指的是查询一个数据库中不存在的数据,导致:
- 缓存中没有命中
- 请求直接落到数据库,增加数据库负担
- 大规模恶意请求可能导致数据库崩溃(如 DDoS 攻击)
如何防止缓存穿透:
- 方法一:使用布隆过滤器(位数组 + 多个哈希函数)快速判断某个 key 是否可能存在,判定不存在则直接返回,不查询数据库(存在假阳性)
- 方法二:使用 NULL 缓存,对于查询后发现不存在的数据,在 Redis 缓存一个短时间的 NULL 值,下次相同请求,直接返回 NULL,避免数据库压力
缓存雪崩指的是大量缓存同时失效,导致:
- 短时间内大量请求落到数据库
- 数据库压力剧增甚至崩溃
- 可能由于 Redis 故障、集群宕机或缓存过期时间相同导致
如何防止缓存雪崩:
- 方法一:设置不同 TTL,避免所有 Key 同时失效(随机过期时间)
- 方法二:分布式缓存(多级缓存),使用多个 Redis 实例进行分片存储,引入本地缓存减少 Redis 依赖,结合 CDN 缓存缓解高并发访问压力
9. 谈谈你对 ceph 的了解?
10. 分布式容灾有哪些方法?
1. 数据库主从复制(Master-Slave Replication)
- 原理:主库写入数据后,同步到从库。
- 场景:MySQL、PostgreSQL、Redis、MongoDB。
- 容灾策略:
- 主库故障时,从库自动切换为主库。
- 数据实时同步或异步同步。
2. 多副本(Replication)
- 数据复制成多份,存储在不同的机器或地域中。
- 典型方案:
- 3 副本机制:如 HDFS、HDFS 等。
- 数据损坏时自动从其他副本恢复。
3. 数据分片(Sharding)
- 数据分散到多个节点,单节点故障影响有限。
- 常用于 Cassandra、HBase、Redis Cluster。
- 容灾策略:
- 节点故障后自动迁移数据。
- 数据重平衡(Rebalance)。
4. 冷备、热备、同城/异地容灾
- 冷备(Cold Backup):数据定期备份到远程磁盘,灾难时手动恢复。
- 热备(Active/Standby):实时同步,故障发生立即切换备机。
- 温备(Warm Backup):备份节点正常运行但不处理用户请求,发生故障快速激活。
5. 多活数据中心(多地容灾)
- 部署在多个地理位置的数据中心,彼此实时或异步同步。
- 一旦某个数据中心发生故障,流量自动切换到其他数据中心。
- 常见策略:
- 同城双活:两个数据中心同时提供服务。
- 异地容灾:跨城市或国家部署数据中心,抵御灾难性事故(如地震、火灾)。
6. 故障转移(Failover)
- 服务宕机时自动转移到备份服务节点。
- 常用技术:
- DNS 切换
- 虚 IP(VIP)漂移(如 Keepalived)
- 心跳检测(Heartbeat)
7. 降级和限流
- 降级:当部分节点故障时,降低服务质量或关闭非核心服务。
- 限流:限流可防止故障扩散,避免雪崩效应。
8. 数据快照(Snapshot)和备份(Backup)
- 快照:短时间内完整复制数据状态。
- 备份:定期保存数据,用于数据恢复。
9. 服务熔断与限流
- 熔断:当服务响应变慢或故障率较高,自动熔断请求,防止故障蔓延。
- 限流:控制请求量,避免超载。
10. 灾难演练和混沌工程
- 通过人工或自动化工具进行故障注入,验证系统容灾能力。
- 如:Chaos Engineering 工具(ChaosBlade、Chaos Mesh、Gremlin)
11. 你理解的设计模式?为什么会有设计模式?你觉得设计一个软件怎么应用这些设计模式?以及你在开发方面的一些心得?
❓主要是面试官看到了我的个人博客,我回复提到了「设计模式」,所以面试官就接着话题往下问了。
设计模式是一系列在软件设计过程中经过反复实践、总结、优化的通用解决方案或经验总结。设计模式体现了一种思想和经验,而不是具体的代码。它是面向对象软件开发过程中的最佳实践,常见的设计模式分为三大类:
- 创建型模式:关注对象的创建,例如工厂方法、抽象工厂、单例、建造者、原型模式等。
- 结构型模式:处理类或对象的组合,例如适配器、装饰器、代理、桥接、组合、外观、享元模式等。
- 行为型模式:描述对象之间的通信和职责划分,例如观察者、策略、命令、模板方法、状态、责任链、迭代器模式等。
为什么会有设计模式?
- 提高复用性:设计模式是经验的总结,能被反复地重用,减少设计过程的试错成本。
- 提供通用解决方案:很多开发中的问题和场景都是重复的,设计模式给出了通用的、经过验证的解决方案。
- 提升代码可维护性和可读性:设计模式使得开发人员之间有一种共同语言,团队更易于交流和协作,有助于提高代码的易读性和易维护性。
- 提高设计的灵活性和扩展性:合理使用设计模式能降低代码耦合度,增强系统扩展性,应对需求变更和演化。
如何应用设计模式?
在实际项目中,并非一定要强行使用设计模式,而应根据实际需求、规模、复杂性等选择合适的模式,遵循以下原则:
分析和识别需求场景:设计模式不是盲目套用的工具,而是用来解决具体问题的。因此需要仔细理解业务需求,识别是否存在典型场景。
选取合适模式:根据具体场景选择最适合的模式。比如:
当需要统一对象创建方式时,使用工厂模式。
当多个对象需要监听同一事件变化时,使用观察者模式。
需要动态给对象添加额外的职责时,选择装饰器模式。
注意适度原则:设计模式的滥用可能带来过度抽象,使简单的问题复杂化。因此必须注意“适度”和“恰当”,不应过度设计。
实践经验总结
先设计,再编码。设计模式应当在设计阶段思考和确定,不是为了模式而模式。
多结合实际项目实践进行总结,只有这样,才能准确把握设计模式的精髓。
开发方面的心得
- 重视基础,少做炫技:软件开发本质是为了解决问题,而不是为了炫耀技术。很多时候用最简单的方案解决问题远好过追求模式、框架的复杂应用。
- 敏捷迭代,避免过度设计:很多时候,我们都无法精确预知项目未来变化,因此初始设计应当足够灵活,避免盲目追求复杂架构。
- 关注代码可读性和维护性:优秀的开发者不仅考虑代码是否运行,更考虑代码是否易于维护和扩展,设计模式在提升代码可读性和维护性上帮助极大。
- 保持开放、持续学习:技术在不断演进,开发人员必须保持开放心态,持续学习新模式、新技术,但同时谨记避免盲目跟风。
12. 一份代码里面写了很多设计模式,这好不好?
不一定是好事,虽然一定程度上提高了代码的可维护性和可扩展性,降低代码耦合。
但是过度设计会造成
- 代码复杂、冗长、难以理解,增加了维护成本;
- 同时影响代码性能
- 滥用设计模式也会导致开发效率降低,比如一个简单的
if-else选择逻辑,如果强行用 策略模式,会导致代码可读性下降
简历拷打
项目应用在哪些场景?
在内存中设计为索引前缀树,那在非易失性存储介质中呢?也是索引前缀树,还是全表查找?
LearnedTLB 是为什么能达到降低 CPU 访存次数?
LearnedTLB 在哪些场景下适用/比较好?
你们模拟的故障注入场景有哪些?怎么注入故障?
如果系统故障注入后,如何进行恢复?
故障注入的报告是什么内容?
博客之类的文章我上去看了一些,有没有让你比较深刻学到很多的内容可以分享一下?
反问环节
Q1:金融是不是对安全要求比较高?
A1:金融这块有几个核心的业务点:
- 安全性:数据安全、法律合规、权限管理(数据存储、通信链路、日志打印)
- 可用性:金融对可用性要求比较高,就比如刚刚为什么我问了很多分布式容灾的一些相关内容,因为你有做过故障这方面的模拟和注入经验,我觉得是一些很可贵的经验。金融对故障演习、故障注入、自动化报表、业务恢复情况比较重视。
- 资金流的状态机:金融会从订单整体状态机的严谨性,流程对账,资金流水的日志方便审计
- 注意 To B 的合作:金融这一行肯定是和国企打交道,所以 to B 的属性比较重,每个银行都有很多特性,特性的多样化你怎么在你的业务上整合起来,不可能给每个银行写一套代码
随心 talk
你刚刚说对老师周五开组会,一般是上午还是下午,要多久。
那比如说你下午在公司订个会议室,你自己跟导师聊一聊也 OK 吧,你自己周五也能来公司吧?一定要去线下参加吗?
如果说你到时候来参加实习,周五就线上参与?
这个不是问题,如果线上的话,我理解也没啥问题。
最后一个问题,你对 Linux 熟悉吗?
如果过了一面,下次面试应该是 3-5 天,或者一周左右。
结果我没办法自己拍,要跟领导沟通一下。
二面(挂)
提前准备
0️⃣ 自我介绍:首先说自己是厦门大学研二在读
- 本科:java、前端、服务器-域名、linux、golang
- 研究生(大四):提前来实验室、C++、杭州实习、西安实习、中科院实习、系统与体系结构
1️⃣ 主要表现对这一块业务感兴趣。
- 聊一聊自己对金融这块业务的理解,问一问某些部分你们都是怎么优化的?然后说一说我的思考?多请教。
- 假设问最近有关注什么事吗 ==> deepseek 5 天开源的内容 (3FS)
- 关于 ceph 这块,实验室刚接了一个国重项目,我想问问您对这块了解吗,关于 ceph 内的故障恢复机制,我个人挺感兴趣的,而且对你们这个业务和方向也感兴趣,感觉自己研究生的一些研究方向和你们业务也相匹配。
- 因为金融业务需要保证高度的可用性,所以我想请教下你们架构上是怎么做分布式容灾的呢?
- 当前团队在研发的金融业务,有哪些主要的技术难点或者挑战?
- 能否介绍一下当前部门使用的主要技术栈和工具链?
- 腾讯金融科技部门日常技术挑战中,最常遇到的难点或技术瓶颈有哪些?
- 金融领域的数据安全和合规管理,你们是怎么保障和实现的?
- 在高并发、高可用、容灾方面,你们具体用了哪些方案或技术?
2️⃣ LeetCode Hot 100
3️⃣ 夯实简历中科院实习的故障注入的内容
4️⃣ 八股文背熟
- 多注重分布式存储、容灾、安全这一块的问题
- 注意事务相关的问题
- MySQL 得看看
- 快排如何把空间复杂度降到 $O(1)$:还是降低不到 O(1),递归调用会带来 $O(logn)~O(n)$ 的栈空间消耗(取决于划分的平衡性),可以通过尾递归优化减少栈空间消耗:每次递归选择较短的子数组进行递归,而较长的子数组用循环来代替递推。
1. 转账业务
- 从你的银行账户里转 1 块钱到我的银行账户里,具体流程?
- 先减还是先增?—— 减
- 根据日志回滚?但是日志也不一定是正确的?
2. rand7() 实现 rand10()
⚠️ 腾讯、字节常考的面试题!
本题重点是相等概率!
本质:就是将 7 进制数转为 10 进制数,即 rand7() * 7 + rand7(),范围为 [14, 56],取模 %10,剔除范围外的数字即可。
面试的时候回答两个 Rand7() 相乘,被腾讯面试官问比如 13 这种数就没办法生成怎么办?
由面试官一步步引导回答出来,不过还是建议用
(rand7() - 1) * 7 + rand7()
1 | 1. rand7() * 7 + rand7() => [14, 56] |
解法 1
1 | // The rand7() API is already defined for you. |
🔥 解法 2
1 | // The rand7() API is already defined for you. |
腾讯 PCG QQ|后台开发
一面(挂)
- unordered_map 与 map 的区别
- C++ 多态怎么实现的
- C++ 异常处理机制
- Redis
- 自旋锁
- 计算机网络 socket 编程
- linux 内存分配机制
- 进程和线程的区别
- 进程间通信方式
- 协程
- 智能指针
- mysql 的 SQL 注入问题
- mysql MVCC
- https 与 http
- 怎么查看线程堆栈大小?正常大小为多少?
- Linux 用户态与内核态的区别?
- 如何理解 Linux 一切皆文件?
x. 项目
x. 两数之和 + 64匹马8赛道最少几轮决前4 —— 11轮/10轮 都可
1. C++ 多态实现
多态主要分为:
- 静态多态(编译期实现):如函数重载、模板。
- 动态多态(运行时实现):通过虚函数(virtual)来实现,常用于继承关系中。
针对动态多态具体来说,编译器会为每个含有虚函数的类创建一个虚函数表(vtable),表中存放该类所有虚函数的地址。每个该类对象内部也会额外存储一个指向虚函数表的指针(vptr)。
当调用虚函数时,编译器在底层会通过以下方式实现:
- 首先,通过对象内部的虚指针找到对应的虚函数表;
- 然后,根据调用的虚函数在表中的位置,找到函数指针;
- 最终,调用这个函数指针指向的实际函数。
⚠️ 注意:
- 每个类对象会多占用一个指针大小(通常8字节或4字节,取决于平台),存储虚指针。
- 每个类只会存在一个虚函数表实例,无论创建多少个对象,都只共享一个虚函数表。
- 虚函数调用相较于普通函数调用会增加一次间接寻址的开销,但开销非常小,通常不会造成明显性能问题。
- 若基类的析构函数不是虚函数,则在用基类指针删除派生类对象时会出现未定义行为,故通常建议将基类析构函数定义为虚函数。
2. C++ 异常处理机制
C++ 的异常处理是通过 try、catch、throw 三个关键字实现的,具体机制如下:
抛出异常(
throw)当程序中出现错误或异常情况时,可以使用
throw抛出一个异常对象。1
2if (denominator == 0)
throw std::runtime_error("除数不能为0");
捕获异常(
try-catch)异常被抛出后,程序控制权会自动转移到相应的
catch块,前提是异常抛出位置位于对应的try块内。1
2
3
4
5try {
int result = divide(x, y);
} catch (const std::runtime_error& e) {
std::cerr << e.what() << std::endl;
}
异常传播与栈展开
- 当异常被抛出后,程序会逐级向上查找匹配的
catch语句,如果找到匹配,则进入相应的处理逻辑;若没有对应的处理,则异常继续向调用栈的上层传播。 - 如果直到
main()函数都未捕获异常,程序会调用std::terminate()终止。
- 当异常被抛出后,程序会逐级向上查找匹配的
异常对象
异常对象通常以值的方式抛出,以引用方式捕获,以避免拷贝开销。
1
catch (const ExceptionType& e) { ... }
栈展开(stack unwinding)
- 当异常抛出后,程序会从抛出点开始逐层向上退出栈帧(函数调用),直到捕获异常为止。
- 在栈展开过程中,局部对象会按顺序调用析构函数释放资源,这保证了资源的正确释放(RAII 机制)。
注意:异常中断了程序的正常流程,从而可能导致对象处于无效或未完成的状态,或者资源没有正常释放等问题。那些在异常发生期间正确执行了“清理”工作的程序被称作异常安全的代码(编写困难)。
3. 自旋锁
自旋锁(Spinlock)是一种用于实现并发控制的同步机制。它的原理非常简单:当线程试图获取锁时,如果锁已被其他线程占用,则该线程不会进入睡眠,而是持续地循环(自旋)检查锁的状态,直到锁被释放为止。
优点:
- 避免线程切换(上下文切换)的开销,减少线程调度成本。
- 在锁被占用时间非常短暂的场景中效率高,比如对共享变量做简单操作(原子操作)。
缺点:
- 长时间占用CPU,造成资源浪费。
- 如果锁持有时间过长,自旋等待将极大降低系统性能。
适用场景:
- 临界区代码执行非常短,线程争用的情况不频繁。
- 多核环境下效果更好,尤其是锁争用时间非常短的时候。
| 自旋锁(Spinlock) | 互斥锁(Mutex) | |
|---|---|---|
| 等待方式 | 忙等待(Busy Waiting) | 线程睡眠(Sleep) |
| CPU资源占用 | 较高(不停地检查锁状态) | 较低(线程阻塞时不占CPU资源) |
| 适用场景 | 临界区短、小规模并发 | 临界区较长的场景 |
1 | std::atomic_flag lock = ATOMIC_FLAG_INIT; |
解释:
- 当锁已被其他线程占用时,当前线程会反复检测锁状态,直到锁被释放。
- 自旋锁的核心就是“自旋等待”,并不会切换到其他线程,或调用系统 API 进入睡眠状态。
4. 计算机网络|Socket 编程
计算机网络中的 Socket 编程 是一种通过网络进行通信的软件开发技术。
- Socket(套接字)是应用层与传输层之间的编程接口。
- 它本质上是对 TCP/IP 协议栈的一种封装,允许开发者实现网络中进程之间的通信。
Socket 分类
通常有两种类型:
| 类型 | 描述 | 常见应用协议 |
|---|---|---|
| 流式套接字(SOCK_STREAM) | 提供面向连接、可靠的传输,基于TCP协议 | HTTP、FTP、SMTP等 |
| 数据报套接字(SOCK_DGRAM) | 提供无连接、不保证可靠传输,基于UDP协议 | DNS、DHCP 等 |
Socket 编程步骤
Socket 编程的一般步骤如下:
服务端流程:
- 创建套接字 (
socket()) - 绑定地址和端口 (
bind()) - 监听连接请求 (
listen()) - 接受连接请求,返回一个新的套接字 (
accept()) - 通过新套接字进行通信 (
recv()/send()) - 关闭套接字 (
close())
服务端代码示例
1 |
|
客户端流程(TCP)
- 创建套接字 (
socket()) - 发起连接请求 (
connect()) - 发送与接收数据 (
send()/recv()) - 关闭套接字 (
close())
客户端示例代码
1 |
|
常用 API 函数
| 函数名 | 功能 |
|---|---|
socket() |
创建套接字描述符 |
bind() |
绑定IP地址和端口 |
listen() |
监听传入连接请求 |
accept() |
接受新的连接,创建通信socket |
connect() |
客户端连接服务端 |
send() |
发送数据 |
recv() |
接收数据 |
close() |
关闭socket |
Socket 编程注意事项:
- TCP是面向连接的,需明确服务端和客户端角色。
- 网络字节序(大端、小端)问题,通常用
htons()和htonl()处理。 - Socket操作可能发生阻塞,需关注阻塞与非阻塞模式。
- 注意处理边界情况(数据发送和接收可能分多次完成)。
5. Linux 内存分配
参考链接:https://zhuanlan.zhihu.com/p/73468738
https://zhuanlan.zhihu.com/p/149581303
阿秀网站
6. SQL 注入是什么?如何防范?
SQL 注入是一种常见的安全漏洞,攻击者利用应用程序未对用户输入进行严格过滤,向数据库注入恶意SQL语句,从而获取、篡改甚至删除数据。
常见示例:
1 | SELECT * FROM users WHERE name = '$name'; |
攻击者可能输入:
1 | ' OR '1'='1 |
导致SQL语句变成:
1 | SELECT * FROM users WHERE name = '' OR '1'='1'; |
直接绕过认证,返回所有用户。
预防SQL注入的措施:
- 使用预编译语句(Prepared Statement),参数化绑定输入。
- 对输入进行严格校验与转义,避免SQL拼接。
- 数据库权限严格控制,避免高权限SQL执行。
7. MySQL MVCC 机制
⚠️ 供学习:DuckDB —— MVCC 和增删改查
MVCC(多版本并发控制)是 MySQL InnoDB 引擎用于控制事务并发的一种机制,其核心思想是:
- 每个事务读到的数据版本可能不同,事务之间无需加锁即可实现并发读取。
- 在事务修改数据时,并不会立刻删除旧数据,而是创建一个新的数据版本,旧版本的数据暂时保留,从而避免读写冲突。
MVCC 依赖的核心技术:
undo log(回滚日志),用于版本链维护。- 每行数据有隐藏字段(如事务 ID)记录版本信息。
快照读(Snapshot Read):
- 读取的是事务开始时数据的版本快照,不会被其他事务干扰。
- 如
SELECT非锁定读。
当前读(Current Read):
- 会读最新版本,并锁定行,防止并发修改(如
SELECT FOR UPDATE)。
8. HTTP 和 HTTPS 区别
HTTP 和 HTTPS 的核心区别在于通信是否加密:
| 区别点 | HTTP | HTTPS |
|---|---|---|
| 安全性 | 明文传输,不安全 | 使用 SSL/TLS 协议,加密传输,更安全 |
| 默认端口 | 80 | 443 |
| 身份认证 | 无认证机制 | 使用证书认证,防止中间人攻击 |
| 性能 | 快(无加密开销) | 较慢(握手与加密开销) |
| 应用场景 | 普通网站,不敏感数据 | 涉及登录、支付、敏感信息场景 |
HTTPS 通信过程简单描述:
- 客户端请求服务器,服务器返回公钥证书。
- 客户端校验证书有效性,生成会话密钥,用公钥加密并返回给服务器。
- 服务器解密获得会话密钥,双方以会话密钥通信。
9. 如何查看线程堆栈(Stack)信息
在 Linux 中,有几种常用方法查看线程堆栈信息:
方法一:使用 gdb 调试工具
1 | gdb -p <进程ID> |
方法二:使用 Linux 系统工具(pstack)
1 | pstack <进程ID> |
方法三:程序中主动打印堆栈
- 如使用
backtrace()系列函数。
常见线程堆栈大小查看
默认情况下,线程栈大小为 8 MB,可以通过 ulimit -s 命令查看。
1 | ulimit -s # 默认线程栈大小 |
或在程序内:
1 | pthread_attr_t attr; |
注意:线程堆栈默认大小通常为8MB(Linux环境),但具体依系统、配置可能有所不同。
10. Linux 中的内核态和用户态有什么区别?
在 Linux 操作系统中,进程运行分为两个模式,即内核态(Kernel Mode) 和 用户态(User Mode):
| 区别维度 | 用户态 (User Mode) | 内核态 (Kernel Mode) |
|---|---|---|
| 权限级别 | 权限受限,仅能访问有限资源 | 权限最高,可访问所有资源和硬件设备 |
| 可执行指令 | 受限指令不能执行,如直接I/O操作 | 所有CPU指令均可执行,包括硬件控制指令 |
| 内存访问 | 有虚拟地址空间隔离,不能直接访问物理内存 | 可直接管理物理内存和地址空间映射 |
| CPU 模式 | CPU运行在非特权模式 | CPU运行在特权模式(Ring 0) |
| 进入方式 | 默认状态,程序启动后即为用户态 | 系统调用、异常、中断等事件进入内核态 |
| 稳定性影响 | 用户态程序崩溃不影响系统稳定性 | 内核态崩溃通常会导致系统崩溃 |
状态切换的场景
- 用户态 → 内核态:
- 程序执行系统调用(如文件读写、网络请求等)
- 发生中断或异常时也会进入内核态
- 内核态 → 用户态:
- 系统调用处理完成,返回用户程序;
- 中断处理完成,返回被中断进程继续执行。
为什么区分内核态与用户态?
这种区分主要是基于以下考虑:
- 安全性: 避免普通用户程序直接访问硬件设备或重要的内核数据,防止用户程序破坏系统。
- 稳定性:用户程序崩溃不影响内核,保护整个系统稳定运行。
- 权限隔离:防止恶意程序或错误程序直接损坏核心系统。
11. 如何理解 Linux 一切皆文件|VFS?
在 Linux 系统中,“一切皆文件” 是一个核心设计哲学,它意味着系统中的几乎所有内容都可以被看作是文件,包括常规文件、目录、设备、进程间通信等。这个设计理念有助于保持系统的一致性和灵活性,使不同类型的资源可以用相同的方式进行访问和操作。
1. VFS 的作用
VFS 主要提供了一套通用的文件系统接口,使得用户可以无感知地操作不同类型的文件系统和设备。例如,应用程序不需要关心底层存储介质使用的是 ext4 还是 XFS,而是通过相同的系统调用(如 open、read、write)来访问文件。
VFS 的主要作用包括:
- 文件系统抽象:支持不同的物理文件系统(如 ext4、NTFS、FAT)。
- 文件对象抽象:无论是普通文件、设备文件,还是管道、套接字,VFS 都用相似的方式处理。
- 统一接口:提供一致的
open()、read()、write()方式,使用户不需要关心底层实现。
2. VFS 结构
VFS 由多个核心数据结构组成:
- super_block:表示挂载的文件系统信息,如磁盘类型、大小等。
- inode:存储文件的元数据(如权限、大小、时间戳)。
- dentry(目录项):表示目录和文件的路径关系,加速文件查找。
- file:表示打开的文件,包含文件描述符等信息。
3. VFS 如何支持“一切皆文件”
| 文件类型 | VFS 视角 | 示例路径 |
|---|---|---|
| 普通文件 | inode + dentry + file |
/home/user/file.txt |
| 目录 | inode + dentry |
/home/user/ |
| 设备文件 | 设备驱动注册为文件 | /dev/sda(磁盘),/dev/tty(终端) |
| 进程信息 | 伪文件系统 /proc |
/proc/1234/cmdline |
| 内核参数 | 伪文件系统 /sys |
/sys/class/net/eth0/ |
| 套接字 | 文件接口 | /var/run/docker.sock |
| 管道 | 通过 VFS 管理 | /tmp/mypipe |
VFS 允许不同类型的文件系统(如 ext4、NFS、tmpfs)在 Linux 内核中无缝协作,同时也将设备、网络等资源抽象为文件。
算法题
[1] 两数之和
思维题
❓问题:一共有 64 匹马,一次只能跑 8 匹(8 个赛道),没有计时器,只能通过比赛判断相对名次。目标是选出最快的前 4 匹马,问至少需要几轮?
1️⃣ 第一步:分组初赛
首先,将 64 匹马分成 8 组,每组 8 匹。
每组各进行一次比赛,一共需要 8 轮 比赛。
- 进行到这里一共用了 8 轮。
- 每组排名确定了,但组与组之间的实力还无法确定。
2️⃣ 第二步:小组冠军对决
将第一轮8个小组赛中的第1名放在一起,再跑一轮,共计 1轮。
- 到此累计轮数:8轮(初赛)+ 1轮 = 9轮。
- 此时确定:
- 第9轮比赛的第1名,就是全局最快的马。
- 第9轮的结果,可以帮我们明确排除掉一些马:
- 比如第9轮中第8名所在小组,其余7匹马都不可能进前4,因为这组冠军本身就在冠军赛中排倒数第1。
- 同理,第9轮的第7名的原始小组,其余马也不可能进入前4。
- 依此类推,还能继续排除。
3️⃣ 第三步:确定剩余竞争马匹
现在仔细分析剩余可能进入前4的马匹有哪些:
- 假设第9轮的前四名分别为:A组第1名,B组第1名,C组第1名,D组第1名(按成绩从好到差排列)。
- 第9轮比赛中:
- 第1名所在小组(A组):A组原来的第2名、第3名、第4名都可能进入前四;
- 第2名所在小组(B组):B组原来的第2名、第3名可能进入前四;
- 第3名所在小组(C组):C组原来的第2名也可能进入前四;
- 第4名所在小组(D组):只有冠军可能进前四,其他名次马匹绝无可能。
- 其余小组(第9轮的第5至8名所在组),其余所有马匹都不可能进前4,完全排除。
因此,目前仍有可能进入前4名的马匹数量:
- 第9轮的前四名:A1, B1, C1, D1 共4匹
- A组的2,3,4名:3匹
- B组的2,3名:2匹
- C组的2名:1匹
- D组的2-8名:0匹
- 其他组全部排除:0匹
一共剩余:4(前四名)+3+2+1 = 10匹。
但是注意:
- 第9轮的第1名(A1)已经确认冠军,不用再跑。
- 目标是找出前四,已确认第1名,实际上仅需再明确第2、3、4名。
- 所以最后一次比赛只需在剩余的10 - 1 = 9匹中选择出最快的3匹即可。
下面的分析就是最好情况下(其中 1 匹马超过 B 即可)的次数了:10 轮
如果最坏情况下,还是需要多跑一轮的。
9匹马,一轮只能跑8匹,因此显然9匹不能一轮搞定。因此必须更优化分析!
但是上面分析中,我们实际少算了一个关键点:
- 实际上,第9轮第4名的马(D1)不可能在第10轮中再被后面的马超越,因为它已证明了自己比所有除ABC之外的其他小组冠军都快,且已经赛过这些剩余的其他组选手。也就是说,第9轮第4名(D1)不会被任何之前的非冠军马超过,所以不需再参与下一轮比赛,实际上可以排除。
因此,重新整理一次:
- 已经确定第1名(A1)。
- 第9轮第4名(D1)已无法被超越,无需参与最后轮次。
- 因此实际需要再比的马匹减少为8匹,正好8赛道跑一轮即可搞定:
- 第9轮的第2名(B1),第3名(C1),需要再确认名次。
- A组的第2、3、4名(3匹)
- B组的第2、3名(2匹)
- C组的第2名(1匹)
加起来正好 8匹。
4️⃣ 第四步:最终决赛(最后1轮)
将上述8匹马跑最后一轮,直接决出前4名中剩余的第2、第3、第4名。
- 到此累计轮数:8轮(初赛)+ 1轮(冠军组赛)+ 1轮(最终确认赛)= 10轮。
✅ 答案:最少需要 10轮 比赛
一般来说是 11 轮。
腾讯 PCG QQ|后台开发
业务主要是做:推荐算法,而非 golang 开发
一面(挂)
业务
- 功能开发(CRUD):golang
- 搜索、推荐算法、AI 落地:对性能比较高,用 C++
- QQ 内部很多历史代码都是 C++,更要求候选人懂 C++
1. 实习与项目拷打
…
‼️2. 什么情况下会用到右值引用?
等价于问题:右值引用的主要用途
右值引用(T&&)主要用于实现移动语义和完美转发:
移动语义: 当一个临时对象或不再使用的资源,需要被高效地“移动”而不是拷贝时,就用到右值引用:
1
2std::vector<int> v1 = {1,2,3};
std::vector<int> v2 = std::move(v1); // 此时v1内容转移给v2,避免深拷贝完美转发: 模板中利用万能引用(forwarding reference)配合
std::forward实现任意类型参数的原始性质传递:1
2
3
4template<typename T>
void wrapper(T&& arg) {
func(std::forward<T>(arg)); // 原样传递arg(左值传左值,右值传右值)
}总结一下右值引用的使用场景:
- 避免不必要的内存拷贝(提升效率)
- 转移资源所有权(移动语义)
- 模板泛型函数完美转发(提高泛型代码通用性)
‼️3. move() 底层原理
std::move() 的底层原理实际上非常简单,它本身并不真正执行移动,而是一个类型转换工具,用来将左值(lvalue)强制转换为右值引用(rvalue reference),从而允许移动语义发生。
一、源码分析(典型实现)
在C++标准库中,std::move() 一般可实现为如下模板函数:
1 | template <typename T> |
上述代码可以解析为:
T&& arg:这是一个万能引用(forwarding reference),能够绑定到左值或右值。remove_reference_t<T>:移除模板参数T可能带有的引用限定符,保证返回的确实是一个右值引用类型。static_cast<remove_reference_t<T>&&>:进行强制类型转换,将传入参数从左值转换为右值引用。
二、原理分析
std::move() 本身没有发生移动动作,它只是一个类型转换工具:
- 转换前:变量(对象)本身是左值,只能调用拷贝构造函数或拷贝赋值。
- 转换后:变量变为右值引用,具备调用移动构造函数或移动赋值的资格。
本质是告诉编译器:“这里的对象我不再需要了,可以放心进行资源的移动操作。”
例如:
1 | std::string str1 = "Hello"; |
三、实际的“移动”如何发生?
实际的移动(资源转移)是通过被调用对象的移动构造函数或移动赋值运算符实现的,而不是通过std::move()实现:
例如,std::string 的移动构造函数的伪代码:
1 | // 移动构造函数示意 |
std::move() 提供右值引用,而真正资源转移的逻辑,由类的移动构造或移动赋值完成。
四、注意事项
std::move()不会清空对象:- 调用
std::move()后的对象处于有效但未指定状态(valid but unspecified state),通常对象变为空或默认状态。 - 你可以继续赋值或析构,但不应该继续访问对象原先的资源。
- 调用
- 移动语义要求类本身支持移动构造或移动赋值:
- 若类本身未定义移动构造或移动赋值,调用
std::move()仍然可能降级成拷贝。
- 若类本身未定义移动构造或移动赋值,调用
| 问题 | 结论 |
|---|---|
std::move()本质是什么? |
类型转换函数,从左值转为右值引用 |
| 真正的移动操作在哪里发生? | 类的移动构造函数或移动赋值运算符 |
| 调用后原对象的状态? | 有效但未指定 |
std::move() 本身几乎没有开销,它只是一个编译期的类型转换工具,真正的开销和行为由类型本身的移动构造和赋值函数决定。
4. 智能指针,shared_ptr 怎么实现自动管理内存?
shared_ptr通过引用计数(reference counting) 实现对堆内存自动管理:
具体实现原理:
shared_ptr内维护两个指针:- 资源指针:指向实际对象的指针。
- 引用计数指针:指向一个额外分配的计数器对象(含引用计数和弱引用计数)。
- 构造时:资源分配一次,引用计数设置为1。
- 复制构造(shared_ptr之间复制):引用计数增加1。
- 析构时:
- 引用计数减1。
- 若引用计数变为0,则自动释放资源(调用delete或自定义deleter)
1 | template<typename T> |
5. shared_ptr 下的多线程问题
shared_ptr对引用计数本身是线程安全的(C++11起):
- 同一个
shared_ptr的多个拷贝对象,在多个线程并发调用拷贝构造、赋值、析构时,不需要额外同步保护。
但对shared_ptr指向对象的访问本身并不保证线程安全:
- 如果多个线程访问同一个对象资源时,需要额外的锁机制保护资源本身:
1 | std::shared_ptr<MyObject> sp = std::make_shared<MyObject>(); |
简单总结:
| 行为 | 是否线程安全? | 说明 |
|---|---|---|
| 引用计数自身 | 是 | 内部使用原子操作 |
| 对象访问 | 否 | 需自行实现同步 |
6. GCC 编译流程
预处理、编译、汇编、链接
GCC的编译过程大致分四步:
- 预处理(Preprocessing):
- 处理宏定义、条件编译、头文件展开。
- 命令示例:
gcc -E main.c -o main.i
- 编译(Compilation):
- 将预处理后的代码(
.i文件)编译成汇编语言(.s文件)。 - 命令示例:
gcc -S main.i -o main.s
- 将预处理后的代码(
- 汇编(Assembly):
- 汇编代码转成二进制目标文件(
.o文件)。 - 命令示例:
gcc -c main.s -o main.o
- 汇编代码转成二进制目标文件(
- 链接(Linking):
- 将一个或多个目标文件(
.o)链接,合并成最终的可执行程序(a.out或其他指定文件名)。 - 命令示例:
gcc main.o -o main
- 将一个或多个目标文件(
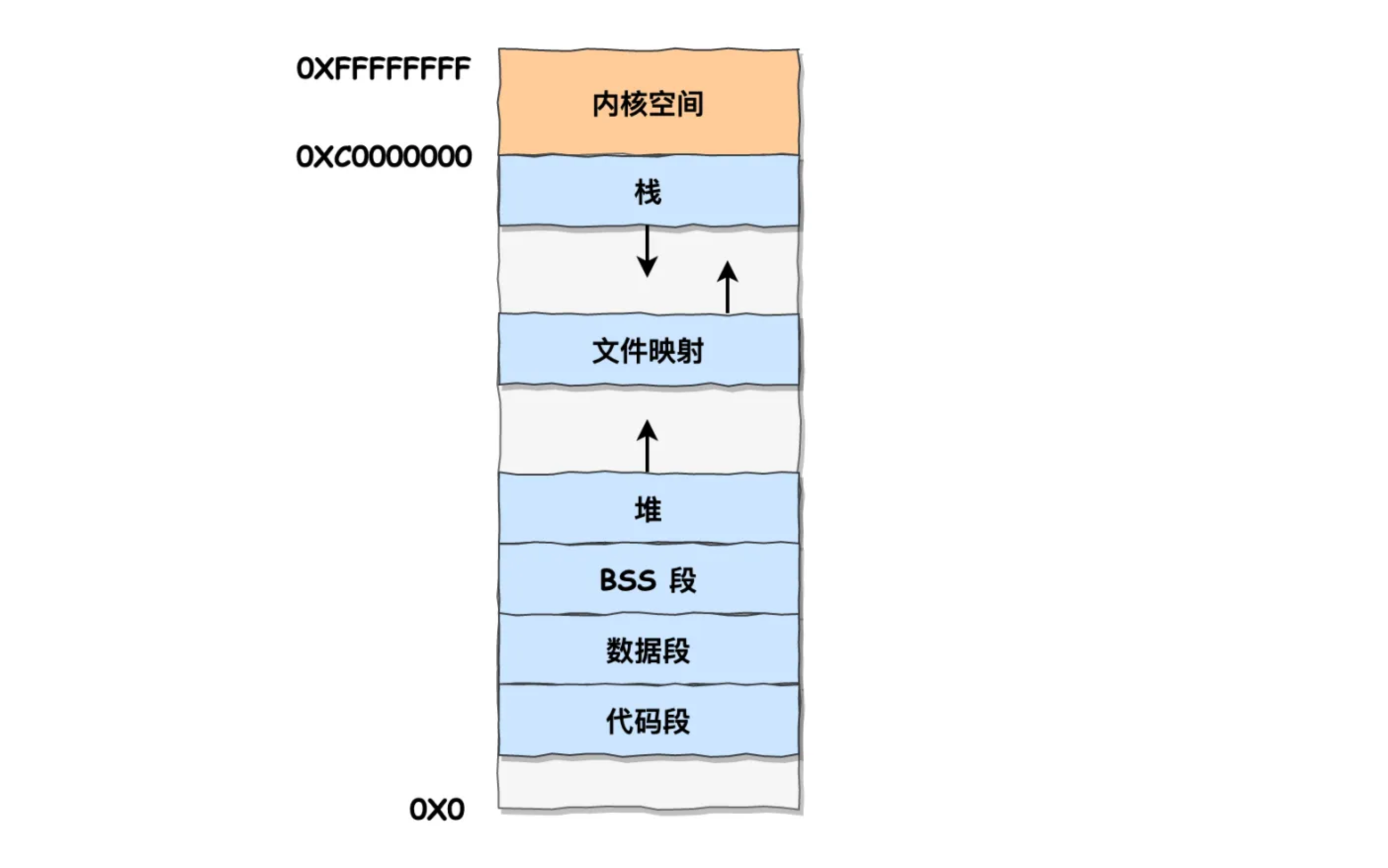
7. 可执行文件加载到内存里,其内存布局是怎样的?
当可执行文件(如Linux ELF格式)加载到内存中运行时,其典型内存布局为:
从低地址到高地址顺序:
| 内存段 | 功能说明 |
|---|---|
| 代码段(text segment) | 存放程序的机器指令(只读、可执行) |
| 数据段(data segment) | 已初始化的全局变量和静态变量 |
| BSS段(bss segment) | 未初始化或初值为零的全局变量和静态变量 |
| 堆(Heap) | 动态分配的内存(由低地址向高地址增长) |
| ↕️ | (动态增长空间) |
| 栈(Stack) | 函数调用栈帧(由高地址向低地址增长) |
具体示意图:
1 | +-----------------------------+ 高地址 |
- 代码段:函数指令
- 数据段:全局或静态变量(初值不为0)
- BSS段:全局或静态变量(初值为0或未初始化)
- 堆段:动态内存(malloc/new)
- 栈段:函数调用的局部变量、调用返回地址、临时变量等
算法题:手撕 LRU
LeetCode LRU 缓存:https://leetcode.cn/problems/lru-cache/description/
1 | struct Node { |
快手深广搜|C++ 开发
一面(挂)
算法题:合并 K 个有序链表
LeetCode: https://leetcode.cn/problems/merge-k-sorted-lists/description/
1 | /** |
时间复杂度
在使用最小堆(或优先队列)合并 K 个升序链表时,时间复杂度主要由以下两个部分组成:
- 初始化最小堆:将 K 个链表的头节点插入最小堆中。由于每次插入操作的时间复杂度为 O(logK),因此这一步的总时间复杂度为 O(K logK)。
- 合并过程:在合并的过程中,需要进行 N 次插入和删除操作,其中 N 是所有链表节点的总数。每次插入和删除操作的时间复杂度均为 O(logK),因此这部分的总时间复杂度为 O(N logK)。
综上,使用最小堆合并 K 个升序链表的总体时间复杂度为 $O(N logK)$。这种方法的优势在于利用最小堆高效地获取当前最小的节点,从而在合并过程中保持链表的有序性。
顺便复习下「堆排序」
1 |
|
项目问题
- 应用场景?
- ART 索引的优势?
- 考虑 PM 成本?
Vivo C/C++ 嵌入式开发
一面(挂)
介绍你的项目和实习
- 就问 OPPO 项目几个问题而已
怎么优化系统性能
- 合理使用缓存机制,如内存缓存、Redis 等
- 利用多线程或多进程技术,让更多的处理器核心参与计算,提升吞吐量
- 选择高效的算法和数据结构可以显著提升系统性能
- 编写高质量的代码,避免冗余计算,减少函数调用和内存分配,合理使用同步和异步操作
- 采用集群等高可用架构,避免单点故障,确保系统在高负载下仍能稳定运行
- 负载均衡,通过将请求分配到多台服务器上,避免单一服务器的性能瓶颈
- 使用消息队列实现高并发下的异步处理,削峰填谷,缓解系统压力
perf工具查看系统性能瓶颈- 开启编译优化
-O2、-O3
C++ 多态怎么实现:静态多态(重载,模板)、动态多态(继承与虚函数)
C++11 新特性有哪些?
- auto 变量自动类型推导、decltype 表达式自动类型推导
- lambda
- 智能指针
- move
- 右值引用
- final、override
- 模板
- nullptr 取代 NULL
- constexpr
- delete
- 范围 for 循环
- 列表初始化
- …
C++ class 和 C struct 的区别
- 默认权限:C struct public、C++ class private;同时 C 语言中不支持继承和多态
嵌入式系统的特点
工作中遇到复杂的问题,如何解决
反问:校招生没有嵌入式经验,会排斥吗
腾讯 CSIG 腾讯云|后台开发
一面(挂)
1. 操作系统中对于物理内存是怎么做管理的?
操作系统设计了虚拟内存,每个进程都有自己的独立的虚拟内存,我们所写的程序不会直接与物理内存打交道。
有了虚拟内存之后,它带来了这些好处:
- 第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
Linux 是通过对内存分页的方式来管理内存,分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在 Linux 下,每一页的大小为 4KB。
最初的内存管理采用固定分区或可变分区(最先适应分配算法、最优适应分配算法、最坏适应分配算法…)
之后才出现了分页、分段,与分区方式互斥
虚拟地址与物理地址之间通过页表来映射,如下图:

页表是存储在内存里的,内存管理单元 (MMU)就做将虚拟内存地址转换成物理地址的工作。
而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。缺页异常会触发
2. C++ 程序有一个全局变量,同时起两个进程跑,该全局变量的地址会一样吗?
应该是考进程间的隔离性
不会一样:即虚拟地址可能一样(如果内存布局完全相同),但是物理地址一定不一样。
具体来说:
进程地址空间独立性: 每个进程都有自己独立的虚拟地址空间。同一个程序启动两次,实际上创建了两个不同的进程,每个进程都有各自的独立地址空间。因此,尽管程序本身是一样的,但两个进程里的全局变量地址是在它们各自的虚拟地址空间里分配的,地址可以看起来相同(因为虚拟地址的布局通常一样),但实际上对应不同的物理内存。
物理地址不同: 虽然可能两个进程中相同的变量虚拟地址看起来是一样的(比如在 Linux 中经常全局变量起始地址会是相似的,例如
0x601040),但实际上操作系统的内存管理机制会通过页表将相同虚拟地址映射到完全不同的物理内存上。举例说明: 比如你定义了一个全局变量:
1
int global_var = 10;
编译运行程序两次,会创建两个不同的进程,比如进程A、进程B。
- 进程A里:
&global_var=0x601040(虚拟地址) - 进程B里:
&global_var=0x601040(虚拟地址)
表面上看起来一样,但它们实际上分别映射到不同的物理页中,实际在内存中的位置并不相同,彼此不会产生冲突。
- 进程A里:
3. 1G 物理内存,代码中申请 2G 内存块(malloc),同时起两个进程会发生什么?
这是一个经典的面试问题,背后涉及虚拟内存管理、内存映射机制和缺页异常的知识。
简而言之:如果【物理内存 + Swap 分区】小于申请的内存大小,那么就有可能发生 OOM(假设没法回收旧页面),因为虚拟内存 = 物理内存 + Swap 分区大小
- 物理内存(RAM):1 GB
- 进程尝试申请:4 GB 内存
- 假设系统启用了 Swap,比如还有 2 GB 的 Swap 空间
- 问题是:还会发生 OOM 吗?
Linux 默认允许 overcommit,也就是说,即使系统没有足够物理内存+Swap,也可能“允许”你申请 4GB。但是等到真正**使用那块内存(写入)**的时候,系统发现分配不出来,就会发生 OOM。
你有 1GB RAM + 2GB Swap = 3GB 实际可用虚拟内存。你请求了 4GB -> 系统可能允许你分配,但用到第 3GB 时,系统发现真没空间了。
📛 此时如果:
- 没有更多 Swap;
- 没法换出其他内存页;
- 系统无法通过页面回收等手段分配新内存;
→ 就会触发 OOM,并且 Linux 会启用 OOM Killer 杀掉你进程,避免系统崩溃。
你是“申请”还是“实际写入”?这个差别很关键!
- malloc / new 只是申请,系统可能只是“画个圈”,并没有真的分配物理页(lazy allocation);
- 只有当你写入内存时(触发页缺失),系统才真正分配页框,如果那时分配失败,才会 OOM。
总结:
- 你真的“写满”了这 4GB 内存;
- 而系统的 RAM + Swap 不足以支撑;
- 并且系统不能释放或交换出其他内存页;
那么最终还是会触发 OOM。
4. 对于这两个进程 malloc 出来的内存块首地址会不会一样?
可能一样,也可能不一样,具体取决于操作系统和内存分配策略,但在大多数现代操作系统(比如 Linux)中,这两个进程 malloc 得到的内存块首地址通常是一样的。
为什么通常会一样?
虚拟地址空间独立: 每个进程拥有独立的虚拟地址空间,因此两个进程可以有相同的虚拟地址,彼此之间不会冲突。这种机制叫虚拟地址空间隔离。
操作系统的内存映射规则: 现代操作系统(特别是 Linux)常使用相似的内存布局策略:
例如 Linux 下程序启动后的虚拟地址空间布局几乎一致:
1
2
3
4
5
6
7
8
9栈空间(高地址)
↓
堆空间(malloc/brk 向上增长)
↓
数据段/BSS段
↓
代码段
↓
操作系统内核(低地址)
因此,两个进程几乎同时启动后,其虚拟地址布局极为类似,两者用
malloc申请的内存,很可能分配到同样的虚拟地址上。
虽然虚拟地址相同,但物理地址不同。每个进程的内存映射到不同的物理内存页,保证了进程间的内存隔离。
并不是100%一样,但一般来说非常常见:
- 如果内存布局完全相同(相同的程序、相同的运行环境、几乎同时启动),虚拟地址往往相同。
- 如果出现地址随机化(如 ASLR 技术打开),地址可能稍微不同。
5. 进程进行了一次 read 操作,请你说一下这个过程?
🔥 追加问题:
- 1️⃣ 用户态转换为内核态,细节一些,怎么转的?
- 2️⃣ 我就写了个 read,也没写其他东西,他是怎么调用内核代码的?
- 3️⃣ 你有办法在用户态写代码去读文件吗,不调用库函数的情况下?
- 不用标准库,只用 syscall,你可以不调用 glibc 的
read(),而是自己写 syscall 汇编代码来触发系统调用- 用户态 I/O 提供了 UIO,
- 4️⃣ 或者你认为底层在读写文件时实际上在操作什么东西?
- 实际上,文件描述符只是用户态的一个索引,它指向内核中的 file 结构。而真正底层在操作的是文件系统定位出的磁盘块,通过驱动发起 DMA(DMA 控制器来搬运数据),把这些块从硬件搬到内存的页缓存中。所以底层操作的实际是设备上的数据块,而不是文件描述符本身。
- 5️⃣ 最后怎么让你的硬件设备把文件弄到内存里?
- 通过系统调用,触发内核层级联动,最终驱动告诉 DMA 控制器去读磁盘扇区,把数据搬到内存中。
程序的内存分布,其中包括内核空间(在内存中),联想一下即可理解。
read 操作全流程
一、进程发起 read 调用
用户态进程想要从文件、管道、网络套接字、或设备中读取数据时,通常会调用系统调用(read()):
1 | ssize_t read(int fd, void *buf, size_t count); |
- 进程将准备好参数:
- 文件描述符
fd(指明从哪里读) - 缓冲区指针
buf(读入到哪里) - 读取字节数
count(读入多少)
- 文件描述符
二、用户态到内核态的切换(陷入内核)
- 调用
read函数后,C库(glibc) 会触发一个CPU陷入内核(trap)操作:- 具体实现一般是通过
syscall指令或中断机制(例如int 0x80或sysenter/syscall指令)。
- 具体实现一般是通过
- CPU权限级别从用户态(ring3)切换到内核态(ring0)。
- 内核从用户态堆栈取出系统调用号(表示
read)和参数。
此时进入内核态。
三、内核态的系统调用处理流程
进入内核后,系统调用处理例程开始运行:
- 保存上下文:内核会保存用户态的寄存器环境到内核堆栈,以便调用结束后能够恢复用户态现场。
- 参数检查和解析
- 检查文件描述符(
fd)是否有效。 - 检查缓冲区地址
buf是否是合法用户空间地址。 - 检查读取的字节数是否合理(不能超过系统限制等)。
- 检查文件描述符(
- 根据文件描述符找到内核文件结构
- 内核根据
fd从进程的文件描述符表中找到对应的文件结构(file结构)。 - 根据文件结构再找到具体的设备或文件的操作方法集(file_operations结构)。
- 内核根据
四、具体数据的读取操作
内核确定文件类型后,调用具体设备或文件系统的read函数。
- 如果是普通文件:
- 内核从进程对应的文件偏移位置(file position)开始,调用文件系统的
read方法,从文件缓存(page cache)或磁盘读取数据。 - 如果数据不在内存(Page Cache 是 Linux 内核用来缓存磁盘文件内容的一块内存区域),就会触发页面缓存缺页:
- 内核调用磁盘驱动程序,通过DMA方式把数据从磁盘读入内存缓存。
- 进程会进入阻塞状态,等待数据从磁盘读入内存完成。
- DMA完成后产生磁盘I/O中断,唤醒进程继续执行。
- 内核将数据从内核缓冲区(page cache)拷贝到用户空间提供的缓冲区
buf中。
- 内核从进程对应的文件偏移位置(file position)开始,调用文件系统的
- 如果是网络socket或管道等:
- 内核检查管道或socket缓冲区是否已有数据。
- 如果没有数据,进程通常阻塞在
wait queue(等待队列)上,等待数据到达。 - 数据到达后,内核再将数据从内核态缓冲区拷贝到用户态缓冲区。
五、内核态到用户态的返回(返回用户态)
- 数据拷贝完成,系统调用返回时:
- 内核将读取到的字节数返回给调用进程(作为
read返回值)。 - 如果读取出错,则返回负数并设置对应的错误码(
errno)。
- 内核将读取到的字节数返回给调用进程(作为
- 内核恢复之前保存的用户态寄存器上下文。
- CPU从内核态返回用户态(通过
iret、sysret等特殊指令),进程恢复执行。
如何在不调用库函数的情况下,对硬件设备进行读写?
👉 可以不调用标准库函数(如read、fread),但:
- 你不能绕过系统调用本身。
- 因为 读文件必须依赖内核提供的能力(文件系统访问、设备 I/O),这些都是用户态无法直接访问的。
方法一:不用标准库,只用 syscall,你可以不调用 glibc 的 read(),而是自己写 syscall 汇编代码来触发系统调用:
示例(x86_64 Linux 下)
1 |
|
🔸这里你没用
read()、open()等库函数,完全绕过了 glibc,只用syscall。
底层其实还是通过 syscall 指令陷入内核,所以你仍然走的是: 用户态 → 内核态 → 文件系统 → 块设备 → 驱动 → 硬件 这条链路。
方法二:手写汇编 syscall(进一步硬核)
你甚至可以直接写汇编触发 syscall:
1 | mov rax, 0 ; SYS_read |
可以嵌入到 C 中用 asm 关键字,或者纯汇编实现。但本质仍然是调内核提供的功能。
完整的内核 I/O 链路
内核中的 I/O 链路是一个比较复杂的流程,涉及到从系统调用层到驱动程序再到硬件控制器,最终完成数据交换。下面用详细且清晰的方式完整描述一下 Linux 内核中典型的 I/O 链路(以磁盘读写为例):
用户进程发起 I/O 请求
⬇️
系统调用层(如read()/write())
⬇️
虚拟文件系统层 (VFS)
⬇️
具体文件系统层(如 ext4、xfs)
⬇️
块设备层(Block Layer)
⬇️
I/O 调度层(如 CFQ、Deadline、noop)
⬇️
通用块设备接口(Generic Block Layer)
⬇️
设备驱动层(如 SATA、NVMe 驱动)
⬇️
硬件接口层(设备控制器,如 AHCI 控制器)
⬇️
硬件设备(磁盘、SSD 等物理设备)
⬇️
设备执行完成,产生硬件中断通知 CPU
⬇️
内核中断处理程序完成后续动作(如唤醒进程)
🔥 下面是一个完整的、详细的 I/O 请求处理链路(以一次文件读取操作为例):
(1)用户进程发起系统调用
- 用户程序调用标准库函数:
read(fd, buf, count); - 陷入内核态,内核获取调用参数。
(2)系统调用层 (sys_read)
- 内核调用
sys_read:- 检查文件描述符有效性;
- 获取内核的文件结构体(struct file)。
(3)虚拟文件系统层 (VFS)
- 内核通过 VFS 层调用文件对应的操作函数,调用对应文件系统的 read 方法:
file->f_op->read_iter(...)
(4)具体文件系统层(如 ext4)
- 文件系统层通过文件的 inode 结构确定要读取的数据位于哪些逻辑块。
- 文件系统根据 inode 中的映射结构确定物理磁盘上的位置(磁盘扇区号)。
(5)块设备层(Block Layer)
文件系统调用块设备接口(bio 接口)发起数据请求。
此时内核创建一个 bio 结构体 表示一次 I/O 请求:
submit_bio()块设备层对 bio 进行进一步封装,形成更底层的 request 结构。
(6)I/O 调度层(IO Scheduler)
- request 进入 I/O 调度器队列,常见调度器如:
- CFQ(Completely Fair Queueing,完全公平队列)
- Deadline
- noop
- BFQ(新版本)
- I/O 调度器决定请求的先后顺序,进行排序和合并优化,减少磁盘寻道延迟。
(7)通用块设备接口(Generic Block Layer)
- I/O 调度器调度好的请求传入通用块设备层。
- 通用块设备层对请求做进一步通用处理,比如:
- 合并相邻请求
- 分发到具体的设备驱动
(8)设备驱动层(Device Driver)
- 通用块设备接口将 request 分发给具体驱动,比如:
- SATA 磁盘驱动 (
ahci.ko) - NVMe 驱动 (
nvme.ko)
- SATA 磁盘驱动 (
- 驱动程序将 request 翻译成硬件控制器能理解的指令集:
- 对于磁盘:ATA/SCSI 命令
- 对于 NVMe:NVMe 命令
- 驱动程序将命令写入设备控制器寄存器,触发 DMA(直接内存访问)数据传输。
(9)硬件接口层(设备控制器)
- 硬件控制器(如 AHCI 控制器)根据命令从物理磁盘读取数据:
- 控制磁盘机械臂移动,进行磁道寻址;
- 寻道完成后,读取数据到控制器缓存;
- 通过 DMA 把数据传输到内存中的内核缓冲区(Page Cache)。
(10)硬件设备完成数据传输(DMA)
- DMA 数据传输完成后,硬件设备发起硬件中断通知 CPU,表示操作完成。
(11)中断处理流程(Interrupt Handler)
- CPU 响应硬件中断,内核执行相应中断处理程序:
- 确认硬件完成状态;
- 标记 request 已经完成;
- 唤醒阻塞在此请求上的进程或任务(如被阻塞的 read 调用)。
(12)返回数据到用户进程
- 唤醒进程后,内核从内核缓冲区(Page Cache)将数据拷贝到用户空间缓冲区。
- 系统调用返回,用户进程继续执行。
⚡ 三、几个关键的数据结构:
- bio:表示一次块设备的 I/O 请求,描述了内存中的缓冲区、目标设备扇区等信息。
- request:更底层的结构,描述了请求的具体物理扇区位置和传输数据量。
- request_queue:存放 request 的队列,由 I/O 调度器管理。
📌 四、再总结一次链路精简版:
1 | 用户进程read |
算法题
146. LRU 缓存
1 | struct Node { |
24. 两两交换链表中的节点
1 | /** |
腾讯 WXG 企业微信|测试开发
一面(挂)
0. 业务介绍
base:广州
测试开发岗位(前后端都需要会):用例管理平台、脑图承载、多端协同编辑、管理业务/研发/测试进度、增量测试、覆盖率、基于大模型自动化测试的工具、版本用户量大需要压测
0. 简历拷打 —— 项目有什么难点吗?
这点需要优化到后续的回答中…
1. C++ 虚函数
虚函数(virtual function)是为了实现 多态 而设计的。基类使用 virtual 关键字修饰成员函数,派生类可以重写该函数,在运行时根据对象的实际类型决定调用哪个函数。
特点:
- 虚函数支持运行时动态绑定。
- 基类析构函数如果有派生类,必须定义为虚函数,否则析构时可能不会调用派生类析构函数,导致资源泄露。
- 虚函数表(vtable)和虚表指针(vptr)是实现机制。
2. new 和 malloc 的区别,二者类型安全吗?
| 特性 | new | malloc |
|---|---|---|
| 语言 | C++ | C |
| 返回类型 | 类型安全,返回实际类型指针 | void*,需强转 |
| 调用构造函数 | ✅ | ❌ |
| 内存分配失败 | 抛出异常 bad_alloc |
返回 NULL |
| 可重载 | ✅(可自定义 new/delete) | ❌ |
| 对象生命周期 | 构造 + 析构 | 仅内存分配 |
类型安全:
new是类型安全的,返回类型是分配对象的实际类型指针。malloc不是类型安全的,返回void*。
3. C++ 多线程一般怎么去实现?
使用 <thread> 头文件中的 std::thread 类可以很方便地创建并管理线程。
常用方式:
1 |
|
4. C++ 用什么创建线程?
主要方式有:
std::thread(C++11 起)std::async(用于异步任务)- 低级:pthread(POSIX 多线程,平台相关)
- 高级库:Boost.Thread,Intel TBB 等
最推荐现代 C++ 使用 std::thread。
5. 同步机制怎么做的?
主要有以下几种方式:
| 同步方式 | 用法 |
|---|---|
std::mutex |
互斥锁,用于保护共享资源 |
std::lock_guard |
自动管理锁,RAII 风格,防止忘记 unlock |
std::unique_lock |
可灵活 unlock/lock,支持条件变量等待 |
std::condition_variable |
线程等待与唤醒 |
std::atomic |
原子变量,避免使用锁的轻量级同步 |
6. 条件变量的使用场景有哪些?
条件变量适用于:
- 生产者消费者模型
- 线程等待某个状态满足(如缓冲区非空)
- 资源准备就绪通知
关键点:
- 需要搭配
std::unique_lock<std::mutex>使用。 - 使用
wait()挂起线程,notify_one()或notify_all()唤醒。
7. C++ 实现生产者消费者场景(多生产者多消费者)
1 |
|
8. 代码中用什么来实现互斥资源量?
✅ 1. 封装成类(推荐)
把资源数量和互斥量封装到一个类里,避免污染全局命名空间,同时更清晰、更安全。
1 |
|
然后在主线程或线程函数中创建并传入对象引用或智能指针:
1 | void worker(ResourcePool& pool, int id) { |
这样你就可以灵活控制资源池了,而且没有全局变量。
✅ 2. 使用 std::shared_ptr 或 std::unique_ptr 管理资源池实例
避免手动管理生命周期:
1 | auto pool = std::make_shared<ResourcePool>(5); |
✅ 3. 用 std::counting_semaphore(C++20)代替资源变量+锁
如果你只关心控制同时访问资源数量,C++20 的 std::counting_semaphore 更优雅:
1 |
|
不用手动管理 mutex,也不用资源计数变量,线程会自动阻塞在 acquire(),直到有资源可用。
9. 线程 thread_local 的作用是什么?
它是线程单独拥有的资源,没办法作为共享资源
thread_local 是 C++11 引入的存储类型说明符,用于为每个线程创建独立的变量副本。
使用场景:
- 每个线程都需要使用一个自己的变量(如缓存、计数器等),避免同步。
- 类似于线程的“全局变量”,但互不干扰。
示例:
1 | thread_local int counter = 0; |
✅ 示例场景:日志系统中用 thread_local 缓存上下文
在多线程程序中,很多系统会给每个线程维护一份独立的日志信息,比如线程 ID、调用栈、临时日志缓存等。如果所有线程都用一个共享变量,会导致锁竞争、效率低下。
这时候就可以用 thread_local 给每个线程一份独立副本!
1 |
|
10. static 关键字作用?
在 C++ 中,static 有不同作用:
- 函数内局部变量:静态存储,生命周期贯穿整个程序(只初始化一次)。
- 类的成员变量:属于类,而非对象,所有对象共享。
- 函数或变量(全局作用域):限制作用域为当前文件(编译单元),实现内部链接。
- 类外静态变量:通常用于全局资源池、计数器等。
11. 死锁产生的条件是什么?
经典的 死锁四条件(同时满足才可能死锁):
- 互斥:资源不能共享。
- 占有并等待:线程持有资源,同时等待其他资源。
- 不剥夺:资源不能被强制释放。
- 循环等待:多个线程形成资源请求的环路。
解决思路:破坏其中任何一个条件即可。
12. 进程间通信的方式有哪些?你用过哪些?
常见 IPC 方式:
| 方式 | 特点 |
|---|---|
| 管道(pipe)/命名管道(FIFO) | 简单、高效,适合父子进程 |
| 消息队列(msg queue) | 类似任务队列,适合异步通信 |
| 共享内存(shm) | 最快,直接访问同一内存区域,需加锁 |
| 信号量 | 控制资源访问(同步) |
| 套接字(socket) | 支持不同主机/网络通信 |
| mmap | 映射共享文件到多个进程内存空间 |
你用过哪个取决于你开发的系统场景,比如服务端常用 socket,系统编程多用 pipe、shm、semaphore。
13. 多进程使用场景?
Web服务器(如 nginx 的 worker)
数据库服务(PostgreSQL)
守护进程(如 init、cron)
高可靠性要求(一个崩了不影响其他)
分布式调度框架(如 Hadoop 的 Task)
14. 多线程使用场景?
计算密集型并发(CPU 多核加速)
I/O 密集型任务并发(如网络请求处理)
GUI 线程 + 后台线程分工
游戏引擎(渲染、物理计算、AI 并发执行)
15. 进程与线程的区别?
| 比较项 | 进程 | 线程 |
|---|---|---|
| 内存空间 | 独立 | 共享(如堆) |
| 创建开销 | 大 | 小 |
| 通信方式 | IPC | 共享内存即可 |
| 崩溃影响 | 互不影响 | 一个线程崩溃可能导致整个进程崩溃 |
| 调度粒度 | 粗 | 细 |
16. 进程上下文切换会发生什么?
发生切换时操作系统会:
- 保存当前进程的寄存器、程序计数器、栈指针等 CPU 状态(上下文)
- 更新 PCB(进程控制块)
- 加载目标进程的上下文,恢复 CPU 状态
- 更新内存页表(虚拟地址)
这是一个非常重的操作(相对线程切换)。
17. 查询发现 SQL 慢查询,怎么处理?
🔥 可以参考链接:”慢SQL”治理的几点思考
给你张表,发现查询速度很慢,你有那些解决方案?
子问题:怎么知道有没有建索引?
子问题:怎么判断索引是否被使用?
- 分析查询语句:使用
EXPLAIN命令分析 SQL 执行计划,找出慢查询的原因,比如是否使用了全表扫描,是否存在索引未被利用的情况等,并根据相应情况对索引进行适当修改。 - 创建或优化索引:根据查询条件创建合适的索引,特别是经常用于
WHERE子句的字段、Orderby排序的字段、Join连表查询的字典、group by的字段,并且如果查询中经常涉及多个字段,考虑创建联合索引,使用联合索引要符合最左匹配原则,不然会索引失效 - 避免索引失效:比如不要用左模糊匹配、函数计算、表达式计算等等。
- 查询优化:避免使用
SELECT *,只查询真正需要的列;使用覆盖索引,即索引包含所有查询的字段;联表查询最好要以小表驱动大表,并且被驱动表的字段要有索引,当然最好通过冗余字段的设计,避免联表查询。 - **分页优化:**针对
limit n,y深分页的查询优化,可以把Limit查询转换成某个位置的查询:select * from tb_sku where id>20000 limit 10,该方案适用于主键自增的表, - 优化数据库表:如果单表的数据超过了千万级别,考虑是否需要将大表拆分为小表,减轻单个表的查询压力。也可以将字段多的表分解成多个表,有些字段使用频率高,有些低,数据量大时,会由于使用频率低的存在而变慢,可以考虑分开。
- 使用缓存技术:引入缓存层,如Redis,存储热点数据和频繁查询的结果,但是要考虑缓存一致性的问题,对于读请求会选择旁路缓存策略,对于写请求会选择先更新 db,再删除缓存的策略。
GPT:
使用 EXPLAIN 分析执行计划
看是否走了索引?是否全表扫描?
添加合适的索引(前缀、联合索引)
拆分复杂 SQL(子查询、JOIN)
规范字段类型(不要 varchar vs int 比较)
分库分表、缓存热点数据
数据量大时考虑归档冷数据
18. 索引底层数据结构是什么?
大多数数据库(如 MySQL InnoDB)使用的是 B+ 树
19. 为什么用 B+ 树而不是哈希表?
| 对比项 | B+ 树 | 哈希表 |
|---|---|---|
| 有序查询 | ✅ | ❌ |
| 范围查询 | ✅ | ❌ |
| 最小/最大值查询 | ✅ | ❌ |
| 磁盘友好 | ✅ | ❌(哈希冲突+链表) |
| 空间利用率 | ✅ | 可能很低(冲突链表) |
哈希适合精准匹配,B+ 树适合数据库查询场景
20. B+ 树怎么存这些数据?
所有数据都存在叶子节点(不同于 B 树)
叶子节点通过指针相连,支持范围查询
非叶子节点只存索引 key,不存数据(占内存小)
多路搜索树,分支因子高,减少磁盘 IO 次数
21. 访问一个网页,中间会发生什么过程?
输入 URL
浏览器查找缓存,若无发起 DNS 查询
DNS 解析出 IP 地址
建立 TCP 连接(可能含 TLS 握手)
发送 HTTP/HTTPS 请求
服务器处理、返回响应
浏览器渲染页面,解析 HTML/CSS/JS
发起后续资源请求(图片、脚本等)
22. 如果响应很慢,可能在哪个环节出现问题?
| 阶段 | 问题可能 |
|---|---|
| DNS | 解析慢、DNS 池老化 |
| TCP 连接 | 三次握手慢 |
| TLS 握手 | 证书链、密钥协商慢 |
| 服务器响应 | 数据库慢、CPU 高负载、缓存未命中 |
| 网络 | 丢包、拥堵 |
| 浏览器渲染 | JS 执行慢、资源大、阻塞 |
23. I/O 多路复用(select、poll、epoll)
I/O 多路复用是一种在单个线程中同时监听多个文件描述符(fd)的方法,在非阻塞 I/O 模型中广泛使用,例如网络服务器中同时监听多个 socket 的可读/可写事件。
常见的三种 I/O 多路复用方式
| 技术 | 特点 | 系统调用 | 文件描述符数量限制 | 通知机制 |
|---|---|---|---|---|
select |
最早的接口,简单 | select() |
有(FD_SETSIZE,默认1024) | 遍历全部 fd |
poll |
改进了 fd 数量限制 | poll() |
无限制(理论上) | 遍历全部 fd |
epoll |
高效,Linux 专属 | epoll_create / epoll_wait |
几乎无限制 | 事件驱动(回调机制) |
🥇1. select 工作原理
- 参数是一个fd 集合(数组),用 bitmap 表示。
- 每次调用
select()都要重新传入 fd 集合。 - 内核遍历这个集合,检测哪些 fd 准备就绪。
- 成本:线性扫描 + 拷贝开销大。
代码示例:
1 | fd_set read_fds; |
🥈2. poll 工作原理
- 传入一个
pollfd[]数组。 - 没有 fd 数量上限限制,但还是要遍历全部 fd。
- 每次都要传入整个数组,重复系统调用,效率不高。
代码示例:
1 | struct pollfd fds[10]; |
🥇🥇3. epoll 工作原理(Linux 专属,最常用)
- 提供三大函数:
epoll_create():创建 epoll 实例epoll_ctl():注册/修改/删除监听的 fdepoll_wait():阻塞等待事件发生
- 核心优势是:事件通知机制(event-driven),不像前面两个要轮询。
- 内核维护一个就绪队列,只返回活跃 fd。
epoll 的两种触发模式:
| 模式 | 特点 | 应用建议 |
|---|---|---|
| LT(Level Trigger) | 默认,状态还在就继续通知 | 简单,适合多数场景 |
| ET(Edge Trigger) | 状态变化才通知一次,必须把数据一次读完 | 性能高,但使用复杂,需要非阻塞 IO |
epoll 示例代码:
1 | int epfd = epoll_create(1024); |
📊 性能对比(大致)
| 接口 | 大量连接场景下性能 | fd 扫描 | 内核空间到用户空间拷贝 |
|---|---|---|---|
select |
差 | 需要全量扫描 | 是 |
poll |
一般 | 需要全量扫描 | 是 |
epoll |
优 | 事件通知,无需扫描 | 否(一次事件返回多个 fd) |
✅ epoll 使用建议
- 所有 socket 设置为 非阻塞(O_NONBLOCK)
- ET 模式下必须 循环读取/写入直到返回 EAGAIN
- 最常用于高并发网络服务(如 nginx、redis、netty)
🚀 小结对比
| 特性 | select | poll | epoll |
|---|---|---|---|
| 平台支持 | 跨平台 | 跨平台 | Linux 专属 |
| fd 限制 | 有 | 无 | 无 |
| 触发机制 | 水平触发 | 水平触发 | 支持边缘 / 水平 |
| 性能 | 差(fd 多时) | 一般 | 高 |
| 使用复杂度 | 简单 | 简单 | 略高(注册 + wait) |
🧠 真实应用场景
select:老旧兼容系统、简单网络工具(不推荐新项目用)poll:稍大系统、兼容跨平台库(如 libevent)epoll:高并发服务端框架(nginx、redis、libuv、netty)
24. 如果 HTTPS 握手失败,你怎么分析原因?
抓包分析(Wireshark)
检查证书链是否完整(浏览器或 openssl s_client)
检查时间是否同步
TLS 协议版本是否兼容(客户端/服务器)
CipherSuite 不兼容
服务器是否强制 SNI / HTTP/2 支持问题
25. 如果证书过期,会有什么表现?
浏览器提示安全警告(NET::ERR_CERT_DATE_INVALID)
curl、API 请求失败,显示证书验证失败
客户端拒绝建立 TLS 连接
HTTPS 请求直接失败或被降级为 HTTP(极少数)
算法题
415. 字符串相加
1 | class Solution { |
230. 二叉搜索树中第 K 小的元素
1 | class Solution { |
354. 俄罗斯套娃信封问题
贪心 + 二分查找:先排序,再按照 LIS 二分贪心模板求最长递增子序列。
因为二者都必须是递增的,所以第二维度需要逆序排序,使得第一维度相同的多个数,最后一个插入的一定是最小值,这样能嵌套的信封最多。
DP 会超时
1 | class Solution { |
美图基础架构|C++ 开发(基础架构)
一面(拒)
主要问项目相关的内容,他自身也没提问八股文相关的知识,主要做「预研」,遂拒。
卓驭智驾端到端|C/C++ 嵌入式开发
一面(OC)
1. 项目拷打
这部分问得比较细致
- OPPO:
ioctl调用了哪些函数、你做了哪些工作 - 中科院软件所:
evenodd实现 - PM 项目:为什么用
art替代bucket,有什么好处(之后记得去看下性能指标提升多少 —— 参考其他论文)
2. C 语言 static 关键字
…
3. C 语言如何实现结构体?
…
4. C++ 如何防止内存泄露?
1️⃣ 代码规范,智能指针或 RAII 机制管理资源
2️⃣ 正确捕获处理异常/回滚式编程
3️⃣ 弱引用解决循环引用问题造成的内存泄露
5. C++ 智能指针?
…
6. C++ 有哪些构造函数?
…
7. C++ 的构造函数可以是虚函数吗?
…
8. ++a 和 a++ 的区别?
…
9. 深拷贝和浅拷贝的区别?
…
10. C++ 11 的新特性
…
11. 如何实现多线程?
…
12. 进程与线程的区别?
…
字节跳动|推荐架构系统实习生
一面
简历
主要简单聊了聊重删的分块算法
算法题
v1 = [2,2,2,2,2,3,3,3]、v2 = [4,4,4,5,5,5,6,6]
压缩表示:
v1 = {{2,5},{3,3}}、v2 = {{4,3},{5,3},{6,2}}
- 向量如何压缩表示
- 乘积、如何优化(非逐步,取二者个数最小值)、不修改原数组怎么实现(双指针)
- 时间复杂度
反问环节
- 业务:抖音视频推荐、C++
二面(挂)
- 项目中遇到最难的问题
- 用代码描述整个流程
腾讯 CSIG 腾讯云|后台开发
一面(挂)
在线笔试,见笔试复盘文档📄:腾讯 CSIG 一面·笔试题
字节跳动 AML 应用机器学习(未投)
…
华为计算产品线|软件开发
机试
技术面
绩点排名、竞赛得奖情况
四次奖学金是本科还是研究生
智能指针
排序算法(快排、堆排、归排
二叉树的前中后序遍历
…
LeetCode 中等题
主管面
自我介绍(过于简洁)
项目拷打(OPPO + 之江实验室):
- oppo 业界最新解决方案
- 之江实验室 和 中科院哪个实习人数较多
- 之江实验室做了什么工作
项目中遇到最大的挑战,如何解决
团队协作遇到冲突怎么处理
论文阅读量有多少
遇到新知识如何快速上手
平时如何调节压力
对华为价值观的理解
你的性格是乐观还是悲观
反问:
- 华为实习生培养制度
- 计算产品线的技术栈
本文由 Yikun Wu 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。




