随着互联网上的信息越来越多,人们陷入了选择困难,人们在阅读信息之前,可能对信息一无所知,只有看到时才知道是否喜欢,人们越来越懒,这就催生出了推荐系统:基于用户广泛的历史行为,预测用户可能感兴趣的信息主动推送,从而达到用户与信息的匹配,由于用户在推荐之前并不知道内容是什么,这扩大了信息的候选范围,进一步提高了潜在的广告位数量,这成为互联网应用的核心竞争力,这是技术与业务的完美结合
背景需求
互联网的一个主要应用就是信息匹配,只有与人发生关系的信息才具有价值,因此人和信息的匹配是互联网应用的核心问题。
信息匹配的方式有多种: 门户/订阅/搜索/推荐。
早期互联网应用以门户展示信息为主,类似专柜陈列的商品,由网站维护人员更新信息,所有人看到的信息都一样。代表就是搜狐/网易/新浪,互联网的技术发展主要推动因素就是计算广告的技术发展,为了提供更多的广告位,让网站能够展示更多的信息,因此由了订阅模式主流是 SRR / 社区等属性,基于社交关注关系,订阅感兴趣的内容主要代表由新浪微博,天涯社区等等,但有很多信息并能通过社交关系获得因此衍生出了搜索需求,用户通过一些 query 来查询到自己想要的信息,这还是信息找人的时代,主要代表就是谷歌/百度/搜狗。 再后来,随着互联网上的信息越来越多,人们陷入了选择困难,人们在阅读信息之前,可能对信息一无所知,只有看到时才知道是否喜欢,人们越来越懒,这就催生出了推荐系统:基于用户广泛的历史行为,预测用户可能感兴趣的信息主动推送,从而达到用户与信息的匹配,由于用户在推荐之前并不知道内容是什么,这扩大了信息的候选范围,进一步提高了潜在的广告位数量,这成为互联网应用的核心竞争力,这是技术与业务的完美结合。
约束条件
- 业务目标: 互联网技术本质上是为了用户需求服务的,推荐系统的目标就是增加留存,使用时长等。
- 低延迟:推荐系统作为核心的在线系统,必须要尽可能的降低延迟,因为每降低 20ms 就可以上线一个策略,来优化业务目标,同时刷首页信息流的延迟感会直接影响用户体验。
- 稳定性: 推荐系统是跟业务目标直接相关的,如果出现问题会直接降低用户留存,使用时长等指标直接影响公司收入,因为通常广告业务需要依赖留存与使用时长进行变现。
- 迭代效率 & 质量:必须做的足够快,推荐系统的迭代速度直接影响公司的竞争能力,同时要对复杂系统保持高迭代效率,势必会导致问题频发,如何保证服务质量将是长久的拉锯战。
- 成本:推荐系统需要大量的存储/计算/网络成本,如何优化庞大的机器资源成本,这将直接创造收入。
技术方案
如果你要给一个朋友推荐一本书你需要怎么做?
第一步: 你要自己读过很多书,这样朋友问你的时候你才能及时的推荐给朋友
第二步: 你应该尽可能的了解这个朋友(你对他的印象/他现在的状态/他想看什么书)
第三步: 基于你对这个朋友的了解以及对你读过的书的了解,潜意识快速筛选出来几十本可以推荐的书
第四步: 然后快速的对这几十本书进行猜测,你这位朋友喜欢这几本书的概率有多大?然后按概率排个序
第五步: 取 topK 结果推荐,基于朋友的反馈,你修正了对朋友兴趣的理解,你的猜测将变得更加准确
第六步: 如果你觉得朋友适合看你刚写的书,那么你会在推荐中夹带私货,强烈安利自己的书(广告)
第七步: 再次推荐书籍时可能会重复推荐,当你发现脑子想到了之前推荐过的书时,你要把他忽略
这个信息匹配的本质就是推荐的基本原理。将人的兴趣量化,再将要推荐的物品特征进行量化,将两个量化值进行计算得到一个分值,然后对所有的计算结果取 topK,返回 topK 的结果,这一过程就是推荐的基本原理。为了实现这一基本步骤,我们发明了多种推荐算法,关于推荐算法的介绍可以参考: 推荐系统公开课 ,接下来的内容将假设你已经对基本的推荐算法有所了解。
根据对推荐算法的分类以及基本原理的理解,我们可以对推荐系统按数据流的构建过程划分为多个模块:候选构建/特征工程/召回系统/排序系统/模型训练/混排系统/消重系统。
基本概念
推荐阅读:推荐系统的基础概念
- item:代表信息的容器,可以是一个视频/文章/商品/广告等等
- 消费:用户浏览 item 所承载的信息,然后发生一系列行为,播放/点赞/收藏/关注/转发/购买等等
- 分发:决定将哪些 item 与用户匹配,展示给用户进行消费的过程就是分发过程
- 打包:推荐系统决定分发哪些 item 给到用户,但是推荐系统不关注 item 承载哪些信息,他只关注 item 具有的特征,因此打包就是将用户能够浏览的信息拼接封装到 item 的这个容器中展示给用户的过程。
- user:消费或者生产 item 的用户
- 候选:准备推荐给用户消费的 item 数据集合
- 预估:深度学习模型的前向传播
- 召回:信息检索的一个过程,通过一个 key 获得一堆相关的 id
- 排序:对召回的 id,按照某种分值进行排序
- 数据流:数据整个生命周期的处理过程
- 特征:物理上客观事物所蕴含信息的数学表达
- 样本:用于机器学习模型训练的数据特征
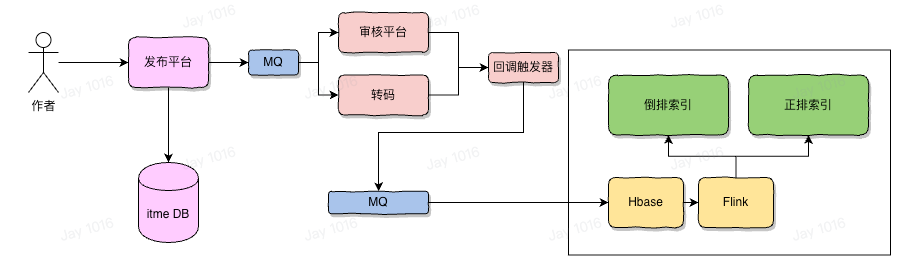
候选构建
当文章/视频 (item) 内容发布后,经过一些审核与处理后需要将 item 存储为易于推荐系统查询的格式,通常就是正排+倒排,正排就是以 itemID 为 key,然后一些 item 相关的结构化属性进行序列化后,存储好的 kv 数据项,而倒排就是以某个属性或者计算的 tag 为 key,value 是一个 timeID 的 list,这两种数据结构覆盖了基本的查询需求,用来为推荐引擎的候选构建提供基础的数据支撑。
所以候选集合本质上就是一个易于推荐引擎查询数据的索引结构,是为推荐提供数据的模块。
特征工程
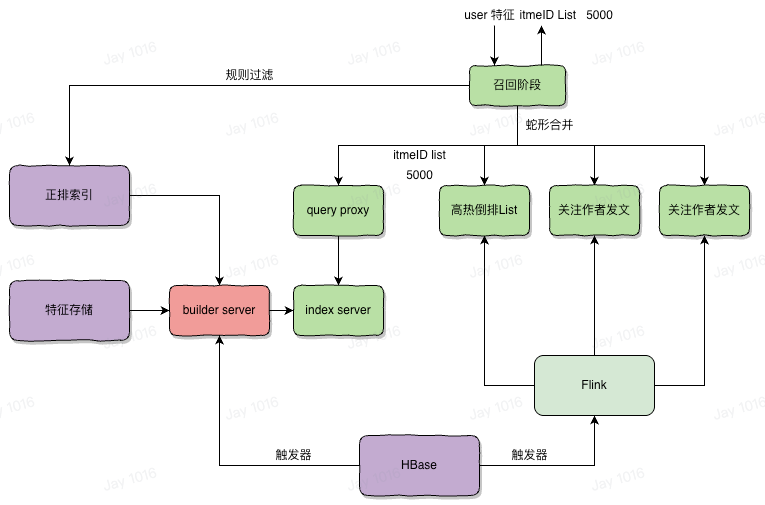
内容候选实在太多,将所有的 item 送入模型进行预估计算量非常大,不可能在秒级返回计算结果,这就要求必须在所有的内容候选中选择最有可能排序在前面的 item,返回一个 top k 的结果,这种大规模的筛选与搜索引擎非常相似,但搜索引擎基于 pagerank 计算的相关性,而推荐召回则基于用户的兴趣与 item 特征之间的相关性,通常通过向量检索,余弦相似度计算两个向量之间的距离来衡量二者的相似程度(分布式向量检索引擎 ),但真实的召回系统通常要有十几种召回策略,这些召回策略会并行使用,然后将召回结果统一合并。
排序系统
训练好的模型,要在线被服务所请求对外提供服务,用户每次主动请求首页的信息流,将携带这个用户的特征信息与返回的一堆 item 的特征,将这些特征信息组成模型的输入,然后经过计算图的计算,输入的特征值与权重参数计算得到一个分值,该分值表示用户如果观看了这个内容将使得损失函数最小化,损失函数被表示为距离业务目标的偏差(使用时长),反过来说就是使得使用时长得到增长。
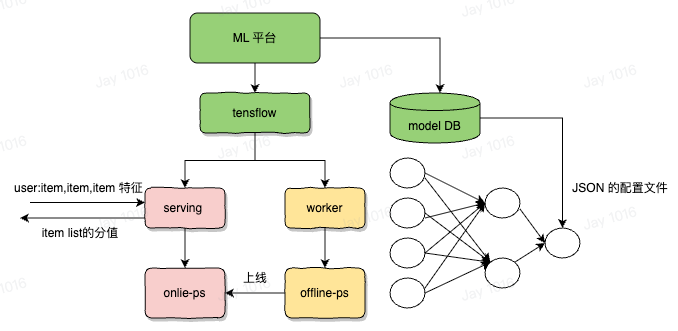
分布式机器学习系统: Parameter Server 设计
为了增强效果,一次召回通常会返回上千条内容,如果直接放在模型中进行预估,同样延迟会超过 1s,不可接受,为此将排序阶段分为粗排和精排两部分,利用一些简单的策略进行快速打分,将上千条内容过滤掉为几百条,粗排的目标是选择最有可能在排序中排在前面的内容,排序部分通常被称之为精排,为了与粗排进行区分,几百条内容通常在过精排的复杂模型时能够保障在毫秒时间内返回,从而在工程实现与业务目标之间取得权衡。
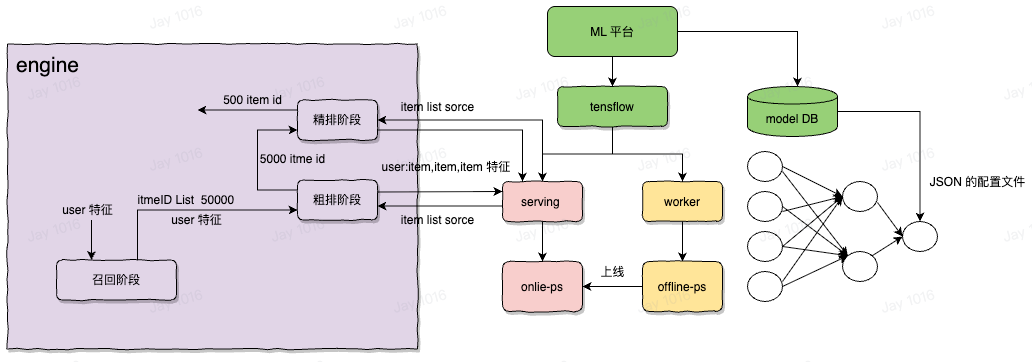
模型训练
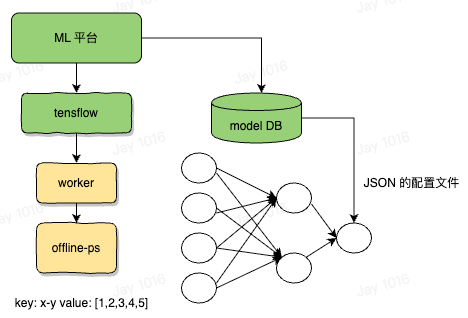
机器学习模型本质上就是一堆参数 + 计算图所组成的数据结构,所谓训练就是先给这些参数一个初始化的值,然后通过输入训练样本,反向传播来更新这些参数值,使其通过计算图可以得到一个使得损失函数最小化的结果。
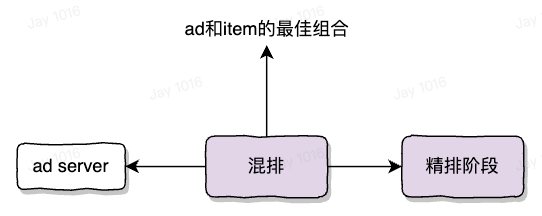
重排(混排)系统
推荐系统需要考虑多样化需求且要满足一定的运营能力,即同一个作者的内容不能集中推荐,这需要一套复杂的规则系统,对推荐系统返回的 item list 整体负责,对于多样性问题,需要考虑一刷内 item 之间的相互影响,相同作者/相似内容等等,为了降低推荐 item 的相似性,需要有一定的打散模型,能够在精排选出的几百条内容中,考虑一次请求整体列表的特征得到整体收益最大的一个排列组合,以便于提高业务目标。
具体的做法,就是使用 dfs 对 300 条内容进行检索,组合的多种排列形式当作候选,通过规则系统和精排打分作为剪枝依据,加速计算过程,最终整体作为输入,过重排模型,得到对排序 list 的打分,选择打分最高的一组 list,进行返回。
当精排返回 top500 条内容后,根据客户端请求的条数进行截断,返回 8-16 条 top 内容,然后在其中插入广告,请求广告系统获取 N 个广告,广告展示在哪个位置上能够使得 ecpm 和用户体验达到最佳状态? 即: 让用户看到最贵的广告,同时要保证用户不那么反感。这是一个高价值的竞拍问题,将广告和 item 使用 dfs 深度遍历组合每一种情况,将这些情况交给算法模型进行评估,打分,选择整体分值最高的排序方式,最终将其放出这一过程就是混排。
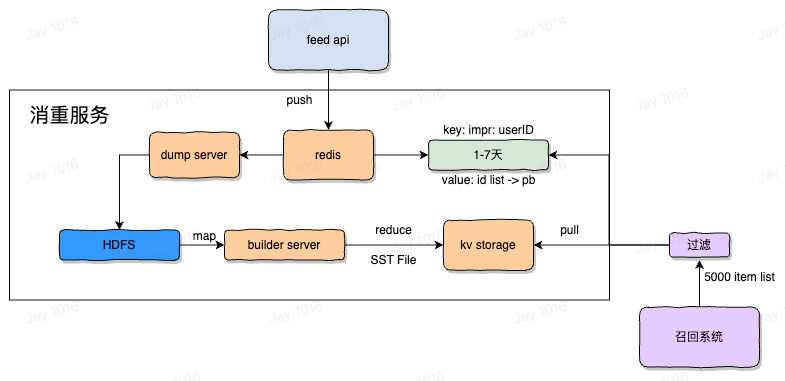
消重系统
用户在一段时间内不能看到相同的内容,这是没有意义的是影响用户体验的,为此我们需要避免同一用户在一段时间内,多次请求到相同内容,之前的召回系统每次召回的内容在一段时间内有可能是相同的,因为向量检索的更新难以做到实时性。这是不符合预期的,所以需要有一个系统记录当前用户历史上浏览过了哪些内容,并在召回后将其过滤掉,这样就能保障送入排序阶段的内容都是用户没有流量过的新内容,消重系统应该尽量在接近用户侧写入,接近召回侧过滤。
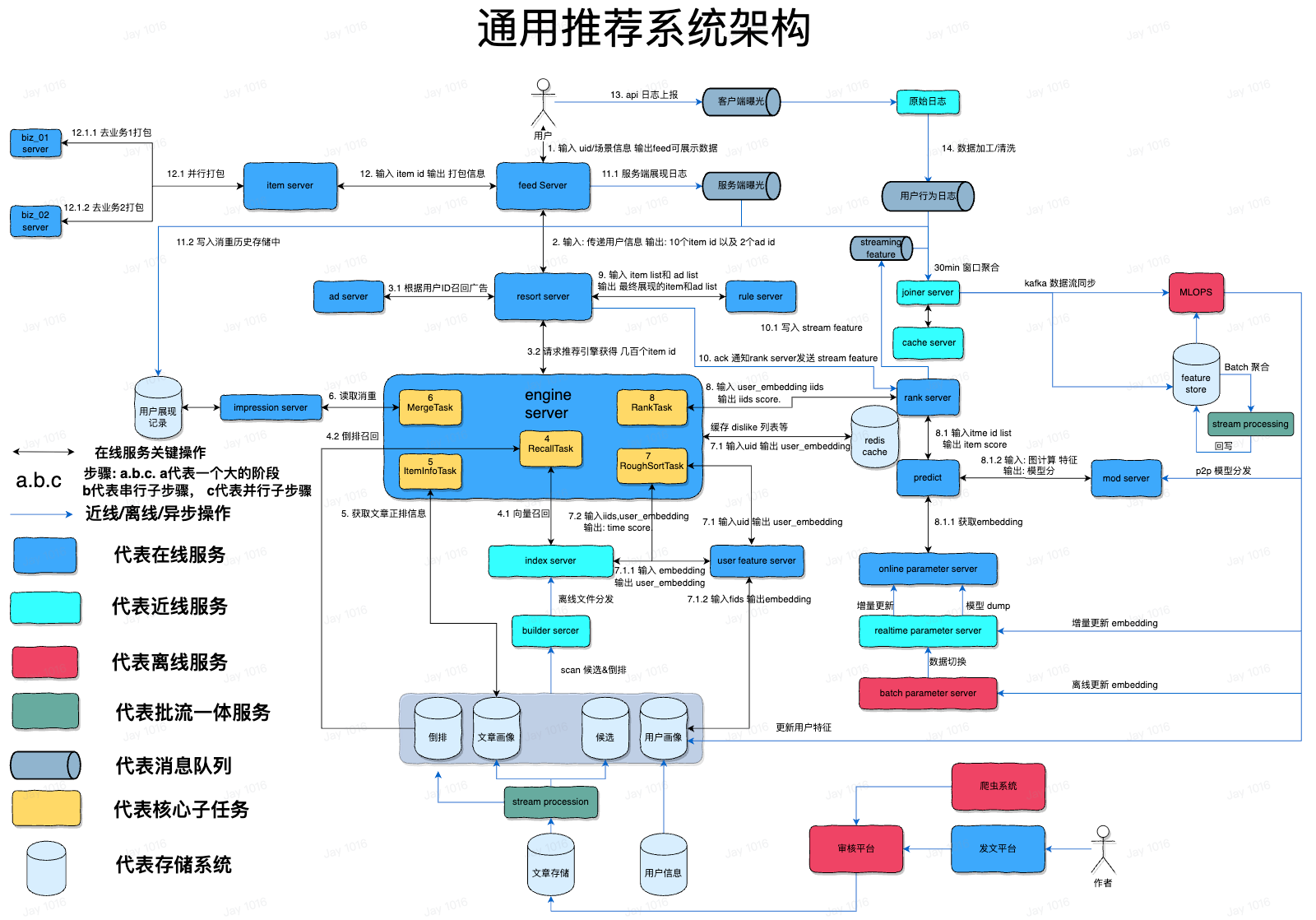
整合架构
- 场景信息包括: 设备信息/当前时间/用户上一刷点赞的 item/用户最近下载了啥 app 等等信息
- 从第二步开始真正的进入推荐引擎,重排 server 将作为信息流广告和推荐业务的入口服务
- 广告是另一个复杂的系统,基于用户的特征,预测对哪些广告更加感兴趣,能够促进转化,此阶段也将真正开始请求推荐系统
- 向量召回输入的是 user 的 embedding 信息,该 embedding 是 user feature server 实时计算的,其返回的是 item id 以及 embedding, 是一个双塔模型,除了主要的向量召回,也会有一些策略召回作为对向量召回的补充,输入的是聚类 id 输出的是 id list
- 通过 item id 获取正排信息,这里会大量查询本地缓存,这些 item 的属性信息用于后续的过滤打散
- 多个召回通道返回的内容需要合并在一起,通常采用蛇形 merge 的方式合并,然后执行一些过滤规则,例如摄政类/曾经刷过的内容/关键词屏蔽/作者屏蔽/版权屏蔽等扽过滤规则,确保放出的 id 有效性较高
- 粗排阶段,通过 uid embedding 和 几千个 item 的 embedding,进行快速的排序预测,通常是一个简单的 ctr 模型,主要是计算快速,在几十毫秒内能够计算出几千个 item 的得分,粗排的目标是尽可能的将高价值的 item 排在前面。
- 精排阶段,主要对推荐效果负责,将以复杂的算法模型作出准确的预估,通常消耗几百毫秒,是推荐最耗时消耗计算资源最多的地方,输入进去的关于 user 和 item 的 embedding 信息,作为模型的输入参数,精排的模型是多目标模型,会有很多输出,每个输出代表一个预测分数,例如转发的概率,点赞的概率,完播的概率等等,每个输出分数对应一个模型,都会讲输入参数入图计算,进入 tf 的 serving 中,根据图计算的 DAG 配置,从配置中确定权重的 id,通常叫做 feature id,根据这个 id 去 ps 中查询具体的 embedding 数值,然后在 worker server 中进行权重的计算,完成前向传播过程,完成计算过程,得到分数,然后精排服务还会对所有的分数过一个融合公式得到一个最终分,该融合公式是认为确定的,通常就是加权平均,根据业务目标调整分数权重即可,最终该融合公式的得分即位排序分
- 精排返回结果后,执行控制流回到重排服务,将 item id 和 ad id 输入规则系统,进行 dfs 检索,选择符合规则策略并取得分最高的一列组合返回,此时决定了最终呈现给用户的 item id 的顺序以及内容
- 此阶段会异步的返回 ack 请求回调精排服务,告诉精排服务哪些 item id 被正式选中进行曝光,此时精排服务会真正的发送 stream feature 用于进行实时的进行训练样本的拼接
- 此时 item id + ad id 的 list 返回到了 feed server,feed server 将 id list 记录到历史消重服务中,该服务是为了记录用户已经看过哪些内容,用于在召回之后将其过滤的操作,同时作为曝光日志(用户看了哪些内容),也会作为训练样本拼接的数据流之一,通常为了覆盖足够的业务逻辑与场景,越接近客户侧的写消重操作效果越好,因为这样将约接近客户真实的曝光行为,越在接近召回的地方做过滤效果越好,因为这样将节约计算资源,确保之后执行的操作都是对可放出的 id 进行的。但过于接近客户侧的写消重,例如由客户端上报写消重,将会因为客户端跨公网传输数据,延迟较高无法实时记录历史数据而不得不放弃
- feed server 主要的作用就是根据 id 以及 id 的类型进行业务打包,也就是根据 id 点查该 id 所对应的内容数据,比如 id 的类型是小视频,则就通过 id 去查询小视频服务返回小视频的播放地址,点赞数/评论数/作者头像等等用于 feed 流展示的数据,如果 id 类型是一个商品,则就去商品服务打包商品的封面图,价格,销量等数据信息,如果是一个广告,则去广告的打包服务查询,总之这一步将根据 id 查询具体体裁内容的展示信息
- 用户真正的看到了 feed 信息,然后根据自己的喜好表达一些消费行为,转发/点赞/评论/停留播放等行为,这些行为会被客户端上报给服务端
- 服务端会对数据进行检查,然后对错误的数据进行剔除,加工转换后用于拼接训练样本,训练样本会进入 joiner server,该 server 将 精排服务上报的 关于 item 的特征信息 (embedding),以及服务端上报的曝光 item id 信息缓存在一个大的 cache 中,缓存 1 小时,客户端上报数据代表着用户对 item 的行为,该数据如果在 1 小时内被回传则说明是正例,将拼接出一个正例样本,如果 1 小时内没有被回传则被认为是负例,为保证正负例一样多,才能保证训练模型不会过拟合,通常会对负例进行采样,丢弃一部分负例,这样保证正负例一样多,进行模型的实时训练,这部分数据就会进入 MLOPS 平台,训练模型参数
本文由 Yikun Wu 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。




